We halve NeRF model size and cut training time by 35% using coreset‑driven neuron pruning, while keeping PSNR within 0.2 dB of the full model.
We examined three neuron‑pruning strategies for Neural Radiance Fields: uniform sampling, importance‑based pruning, and a coreset‑driven approach. Our experiments show that the coreset method reduces the MLP size by roughly 50 % and accelerates training by about one‑third, with only a minor loss in visual fidelity (PSNR drop of 0.2 dB).
TL;DR
Neuron‑level pruning can halve NeRF model size and speed up training by 35 %.
Our coreset method keeps PSNR at 21.3 dB vs. 21.5 dB for the full model.
The approach outperforms random uniform sampling and simple importance scores.
Why it matters
Neural Radiance Fields produce photorealistic 3D reconstructions, but their multilayer perceptrons (MLPs) are notoriously large and slow to train, often requiring days of GPU time. Reducing the computational footprint without sacrificing visual quality opens the door to real‑time applications, mobile deployment, and large‑scale scene generation. By exposing and exploiting latent sparsity in NeRF’s fully‑connected layers, we provide a practical pathway toward more efficient neural rendering pipelines.
How it works
We start from a standard NeRF MLP (256 × 256 neurons per hidden layer). For each neuron we compute two scores: the average magnitude of its incoming weights ( win ) and the average magnitude of its outgoing weights ( wout ). The outgoing score correlates more strongly with final rendering quality, so we prioritize neurons with higher wout. Using these scores we construct a coreset, a small, representative subset of neurons, that preserves the functional capacity of the original network. The selected neurons are then re‑wired into a compact MLP (e.g., 128 × 128 or 64 × 64), and the model is retrained from scratch. Uniform sampling simply drops neurons at random, while importance pruning drops those with the lowest wout or win scores; both are less informed than the coreset selection.
What we found
Across three benchmark scenes the coreset‑driven pruning consistently delivered the best trade‑off between efficiency and quality.
Model size shrank from 2.38 MB to 1.14 MB (≈ 50 % reduction). Parameters dropped from 595 K to 288 K.
Training time per 100 k iterations fell from 78.75 min to 51.25 min (≈ 35 % faster).
Peak signal‑to‑noise ratio decreased only from 21.5 dB to 21.3 dB (0.2 dB loss).
Uniform sampling to 64 × 64 neurons caused PSNR to plunge to 16.5 dB and model size to 0.7 MB, demonstrating that random removal is detrimental.
Importance pruning using wout preserved PSNR at 20.0 dB, better than using only win or the product of both.
Visual inspections confirmed that the coreset‑pruned models are indistinguishable from the full model in most viewpoints, while aggressive pruning shows only minor loss of fine detail.
Key equation
This converts the mean‑squared error between rendered and ground‑truth images into a decibel scale, allowing us to quantify the tiny fidelity loss introduced by pruning.
Limits and next steps
Our study focuses on static scenes and a single MLP architecture; performance on dynamic scenes or alternative NeRF variants remains untested. Moreover, we retrain the pruned network from scratch, which adds a brief warm‑up cost. Future work will explore layer‑wise pruning, integration with parameter‑efficient transfer learning, and joint optimization of pruning and quantization to push efficiency even further.
FAQ
Does pruning affect rendering speed at inference time?
Yes, a smaller MLP evaluates faster, typically yielding a modest inference‑time gain in addition to the training speedup.
Can we prune beyond 128 × 128 neurons?
We observed noticeable PSNR drops (≈ 1 dB) when compressing to 64 × 64, so deeper compression is possible but requires application‑specific quality tolerances.
Read the paper
Ding, T. K., Xiang, D., Rivas, P., & Dong, L. (2025). Neural pruning for 3D scene reconstruction: Efficient NeRF acceleration. In Proceedings of AIR-RES 2025: The 2025 International Conference on the AI Revolution: Research, Ethics, and Society (pp. 1–13). Las Vegas, NV, USA.
We present a 3‑D CNN pipeline that detects dust storms from MODIS data with 91.1% accuracy while cutting training time by 21‑fold, enabling near‑real‑time monitoring.
We built a three‑block 3‑D convolutional network that learns spatial‑spectral patterns from MODIS Terra and Aqua imagery, then added system‑level tricks, memory‑mapped I/O, precomputed patch indices, large‑batch training, torch.compile, and mixed‑precision, to create the accelerated 3DCNN+ variant.
We detect dust storms from MODIS multispectral imagery using a 3‑D CNN pipeline.
Our optimized 3DCNN+ reaches 91.1% pixel‑level accuracy with a 21× training speedup.
The combination of memory‑mapped data handling and mixed‑precision training makes near‑real‑time inference feasible.
Why it matters
Dust storms degrade air quality, threaten aviation safety, and impact climate models. Rapid, reliable detection from satellite data is essential for public‑health alerts and operational forecasting. Traditional remote‑sensing pipelines struggle with the sheer volume of MODIS granules and with the latency introduced by heavyweight deep‑learning models. By drastically reducing training time and enabling full‑granule inference, our approach brings dust‑storm monitoring closer to real‑time operation, supporting timely decision‑making for agencies worldwide.
How it works
We first collect MODIS Terra and Aqua observations, each providing 38 spectral channels at 1‑km resolution. Missing pixels are filled using a local imputation scheme, then each channel is normalized to zero mean and unit variance. From each granule we extract overlapping 5 × 5 × 38 patches, which serve as inputs to a three‑block 3‑D convolutional neural network. The network learns joint spatial‑spectral features that distinguish dust‑laden pixels from clear sky, water, and vegetation. During training we compute a weighted mean‑squared error loss that emphasizes high‑intensity dust regions. The optimized 3DCNN+ variant adds five system‑level tricks: (1) memory‑mapped storage of the full dataset, (2) precomputed indices that guarantee valid patch centers, (3) large‑batch training (up to 32 768 patches per step), (4) torch.compile‑based graph optimization, and (5) automatic mixed‑precision arithmetic. Together these enable fast GPU utilization and dramatically shorter training epochs.
What we found
Our experiments used 117 MODIS granules (100 for training, 17 for testing) that span deserts, coastal regions, and agricultural lands. The baseline 3DCNN achieved 91.1% accuracy and a mean‑squared error (MSE) of 0.020. After applying the five optimizations, 3DCNN+ retained the same 91.1% accuracy while reducing MSE to 0.014. Most importantly, the total wall‑clock training time dropped from roughly 12 hours to under 35 minutes, a 21‑fold speedup. Inference on a full granule (≈1 GB of radiance data) runs in less than two seconds on an A100 GPU, confirming that near‑real‑time deployment is practical.
Pixel‑level classification accuracy: 91.1% (consistent across all test regions).
Weighted MSE for the optimized model: 0.014, reflecting tighter fit on high‑dust pixels.
Training speedup: 21× using the 3DCNN+ system enhancements.
Data efficiency: memory‑mapped I/O reduced RAM usage by more than 90%, allowing us to train on the entire MODIS archive without down‑sampling.
Key equation
The weighted MSE (WMSE) assigns larger weights to pixels with strong dust signatures, ensuring that the loss focuses on the most scientifically relevant portions of the scene.
Limits and next steps
While 3DCNN+ delivers high accuracy and speed, we observed three recurring sources of error that limit performance:
Label imbalance: Dust pixels represent a small fraction of all MODIS samples, causing the model to under‑represent rare dust events.
Spatial overfitting: The receptive field of three‑by‑three convolutions can miss larger‑scale dust structures that extend beyond the 5 × 5 patch.
Limited temporal context: MODIS provides only a single snapshot per overpass; without multi‑temporal cues the model sometimes confuses dust with bright surfaces.
To address these issues, we are exploring transformer‑based architectures that can aggregate information over larger spatial extents and multiple time steps. In particular, the proposed Autoregressive Masked Autoencoder Swin Transformer (AR‑MAE‑Swin) constrains model capacity by reducing the effective Vapnik–Chervonenkis (VC) dimension by a factor , which our theoretical analysis predicts will improve sample efficiency by roughly 30%. Future work will also incorporate self‑supervised pretraining on unlabeled MODIS sequences, and will test the pipeline on other aerosol phenomena such as smoke and volcanic ash.
FAQ
Can the pipeline run on commodity hardware?
Yes. Because the bulk of the data resides on disk and is accessed via memory‑mapping, only a small fraction needs to be loaded into RAM. Mixed‑precision training further reduces GPU memory requirements, allowing the model to run on a single modern GPU (e.g., RTX 3080) without sacrificing accuracy.
How does the weighted loss affect dust‑storm maps?
The weighted mean‑squared error gives higher penalty to mis‑classifications in regions with strong dust reflectance. This focuses the optimizer on the most hazardous pixels, resulting in cleaner, more reliable dust masks that align with ground‑based observations.
Read the paper
For a complete technical description, dataset details, and the full theoretical analysis, please consult the original manuscript.
Gates, C., Moorhead, P., Ferguson, J., Darwish, O., Stallman, C., Rivas, P., & Quansah, P. (2025, July). Near Real-Time Dust Aerosol Detection with 3D Convolutional Neural Networks on MODIS Data. In Proceedings of the 29th International Conference on Image Processing, Computer Vision, & Pattern Recognition (IPCV’25) of the 2025 World Congress in Computer Science, Computer Engineering, and Applied Computing (CSCE’25) (pp. 1–13). Las Vegas, NV, USA.
We present a comprehensive overview of the rapid progress in legal NLP, its systematic organization, and the pathways we see for future research.
A detailed survey of legal NLP advances, taxonomy of methods, and future research directions.This survey maps hundreds of recent studies onto a clear taxonomy of tasks, methods, word embeddings, and pre‑trained language models (PLMs) used for legal documents, and highlights the most effective pairings as well as the gaps that still need attention.
TL;DR
We reviewed a large body of literature that covers multiclass classification, summarization, information extraction, question answering, and coreference resolution in legal texts.
All papers agree on a taxonomy that links traditional machine‑learning methods, deep‑learning architectures, and transformer‑based PLMs to specific legal document types.
Our synthesis shows that domain‑adapted PLMs (e.g., Legal‑BERT, Longformer, BigBird) consistently outperform generic models, especially on long documents.
Key gaps remain in coreference resolution and specialised domains such as tax law and patent analysis.
Why it matters
Legal texts are dense, highly structured, and often lengthy. Automating their analysis improves efficiency, reduces human error, and makes legal information more accessible to practitioners, regulators, and the public. Across all inputs, authors stress that NLP has become essential for handling privacy policies, court records, patent filings, and other regulatory documents. By extracting and summarising relevant information, legal NLP directly supports faster decision‑making and broader access to justice.
How it works
We distilled the methodological landscape into five core steps that recur across the surveyed papers:
Task definition. Researchers first identify the legal NLP problem—classification, summarisation, extraction, question answering, or coreference resolution.
Data preparation. Legal corpora are collected (privacy policies, judgments, patents, tax rulings, etc.) and annotated using standard schemes.
Embedding selection. Word‑level embeddings such as Word2Vec or GloVe are combined with contextualised embeddings from PLMs.
Model choice. Traditional machine‑learning models (SVM, Naïve Bayes) and deep‑learning architectures (CNN, LSTM, BiLSTM‑CRF) are evaluated alongside transformer‑based PLMs (BERT, RoBERTa, Longformer, BigBird, SpanBERT).
Evaluation & fine‑tuning. Performance is measured on task‑specific metrics; domain‑adapted PLMs are often further pre‑trained on legal corpora before fine‑tuning.
This workflow appears consistently in the literature and provides a reproducible blueprint for new legal NLP projects.
What we found
Our synthesis highlights several recurring findings:
Comprehensive taxonomy. All sources agree on a systematic mapping of methods, embeddings, and PLMs to five principal legal tasks.
Transformer dominance. Transformer‑based PLMs, especially BERT variants, are the most frequently used models across tasks, showing strong gains over traditional machine‑learning baselines.
Long‑document handling. Architectures designed for extended context windows (Longformer, BigBird) consistently outperform standard BERT when processing lengthy legal texts.
Domain adaptation pays off. Custom legal versions of PLMs (Legal‑BERT, Custom LegalBERT) repeatedly demonstrate higher accuracy on classification, extraction, and question‑answering tasks.
Benchmarking efforts. Several inputs describe unified benchmarking frameworks that compare dozens of model‑embedding‑document combinations, providing community resources for reproducibility.
Understudied areas. Coreference resolution and specialised domains such as tax law receive relatively little attention, indicating clear research gaps.
Limits and next steps
While the surveyed work demonstrates impressive progress, common limitations emerge:
Interpretability. Many high‑performing models are black‑box transformers, raising concerns for compliance‑sensitive legal applications.
Resource demands. Large transformer models require substantial computational resources; lighter alternatives (DistilBERT, FastText) are explored, but often sacrifice some accuracy.
Data scarcity in niche domains. Certain legal sub‑fields (e.g., tax law, patent clause analysis) lack large, publicly available annotated datasets.
Future research in our community should therefore focus on:
Developing more interpretable, domain‑specific architectures.
Extending multilingual and multimodal capabilities to cover diverse jurisdictions.
Creating benchmark datasets for underrepresented tasks, such as coreference resolution.
Designing efficient training pipelines that balance performance with computational cost.
FAQ
What are the main legal NLP tasks covered?
Multiclass classification, summarisation, information extraction, question answering & information retrieval, and coreference resolution.
Which model families are most commonly used?
Traditional classifiers (SVM, CNN, LSTM) and transformer‑based PLMs such as BERT, RoBERTa, Longformer, BigBird, and specialised variants like Legal‑BERT.
Do transformer models handle long legal documents?
Yes. Longformer and BigBird are repeatedly cited as more effective for lengthy texts because they can process longer token windows.
Is domain‑specific pre‑training important?
All sources agree that adapting PLMs with legal corpora (custom legal embeddings) consistently improves performance across tasks.
What are the biggest open challenges?
Improving coreference resolution, expanding coverage to niche legal domains, and enhancing model interpretability while keeping resource use manageable.
Read the paper
For the full details of our analysis, please consult the original article.
Quevedo, E., Cerny, T., Rodriguez, A., Rivas, P., Yero, J., Sooksatra, K., Zhakubayev, A., & Taibi, D. (2023). Legal Natural Language Processing from 2015-2022: A Comprehensive Systematic Mapping Study of Advances and Applications. IEEE Access, 1–36. http://doi.org/10.1109/ACCESS.2023.3333946
We review 88 multimodal ML papers, highlighting BERT and ResNet for text‑image tasks, fusion methods, and challenges like noise and adversarial attacks.
We systematically surveyed the literature to identify the most common pre‑trained models, fusion strategies, and open challenges when combining text and images in machine learning pipelines.
TL;DR
We reviewed 88 multimodal machine‑learning papers to map the current landscape.
BERT for text and ResNet (or VGG) for images dominate feature extraction.
Simple concatenation remains common, but attention‑based fusion is gaining traction.
Why it matters
Text and images together encode richer semantic information than either modality alone. Harnessing both can improve content understanding, recommendation systems, and decision‑making across domains such as healthcare, social media, and autonomous robotics. However, integrating these signals introduces new sources of noise and vulnerability that must be addressed for reliable deployment.
How it works (plain words)
Our workflow follows three clear steps:
Gather and filter the literature – we started from 341 retrieved papers and applied inclusion criteria to focus on 88 high‑impact studies.
Extract methodological details – for each study we recorded the pre‑trained language model (most often BERT or LSTM), the vision model (ResNet, VGG, or other CNNs), and the fusion approach (concatenation, early fusion, attention, or advanced neural networks).
Synthesise findings – we counted how frequently each component appears, noted emerging trends, and listed the recurring limitations reported by authors.
What we found
Feature extraction
We observed that BERT is the most frequently cited language encoder because of its strong contextual representations across a wide range of tasks.
For visual features, ResNet is the leading architecture, with VGG also appearing regularly in older studies.
Fusion strategies
Concatenation – a straightforward method that simply stacks the text and image embeddings – is still the baseline choice in many applications.
Attention mechanisms – either self‑attention within a joint transformer or cross‑modal attention linking BERT and ResNet embeddings – are increasingly adopted to let the model weigh the most informative signals.
More complex neural‑network‑based fusions (e.g., graph‑convolutional networks, GAN‑assisted approaches) are reported in emerging studies, especially when robustness to adversarial perturbations is a priority.
Challenges reported across the surveyed papers
Noisy or mislabeled data – label noise in either modality can degrade joint representations.
Adversarial attacks – malicious perturbations to either text or image streams can cause catastrophic mis‑predictions, and defensive techniques are still in early development.
Limits and next steps
Despite strong progress, several limitations persist:
Noisy data handling: Existing pipelines often rely on basic preprocessing; more sophisticated denoising or label‑noise‑robust training is needed.
Dataset size optimisation: Many studies use benchmark collections (Twitter, Flickr, COCO) but do not systematically explore the trade‑off between data volume and model complexity.
Adversarial robustness: Current defenses (e.g., auxiliary‑classifier GANs, conditional GANs, multimodal noise generators) are promising but lack thorough evaluation across diverse tasks.
Future work should therefore concentrate on three fronts: developing noise‑resilient preprocessing pipelines, designing scalable training regimes for limited multimodal datasets, and building provably robust fusion architectures that can withstand adversarial pressure.
FAQ
What pre‑trained models should we start with for a new text‑image project?
We recommend beginning with BERT (or its lightweight variants) for textual encoding and ResNet (or VGG) for visual encoding, as these models consistently achieve high baseline performance across the surveyed studies.
Is attention‑based fusion worth the added complexity?
Our review shows that attention mechanisms yield richer joint representations and improve performance on tasks requiring fine‑grained alignment (e.g., visual question answering). When computational resources allow, we suggest experimenting with cross‑modal attention after establishing a solid concatenation baseline.
Read the paper
Rashid, M. B., Rahaman, M. S., & Rivas, P. (2024, July). Navigating the Multimodal Landscape: A Review on Integration of Text and Image Data in Machine Learning Architectures. Machine Learning and Knowledge Extraction, 6(3), 1545–1563. https://doi.org/10.3390/make6030074Download PDF
As we gather around the table this Thanksgiving, it’s the perfect time to reflect on and express gratitude for the remarkable strides made in machine learning (ML) over recent years. These technical innovations have advanced the field and paved the way for countless applications that enhance our daily lives. Let’s check out some of the most influential ML architectures and algorithms for which we are thankful as a community.
1. The Transformer Architecture
Vaswani et al., 2017
We are grateful for the Transformer architecture, which revolutionized sequence modeling by introducing a novel attention mechanism, eliminating the reliance on recurrent neural networks (RNNs) for handling sequential data.
Key Components:
Self-Attention Mechanism: Computes representations of the input sequence by relating different positions via attention weights.
Multi-Head Attention: Allows the model to focus on different positions by projecting queries, keys, and values multiple times with different linear projections. where each head is computed as:
Positional Encoding: Adds information about the position of tokens in the sequence since the model lacks recurrence.
Significance: Enabled parallelization in sequence processing, leading to significant speed-ups and improved performance in tasks like machine translation and language modeling.
2. Bidirectional Encoder Representations from Transformers (BERT)
Devlin et al., 2018
We are thankful for BERT, which introduced a method for pre-training deep bidirectional representations by jointly conditioning on both left and right contexts in all layers.
Key Concepts:
Masked Language Modeling (MLM): Randomly masks tokens in the input and predicts them using the surrounding context. Loss Function: where is the set of masked positions.
Next Sentence Prediction (NSP): Predicts whether a given pair of sentences follows sequentially in the original text.
Significance: Achieved state-of-the-art results on a wide range of NLP tasks via fine-tuning, demonstrating the power of large-scale pre-training.
3. Generative Pre-trained Transformers (GPT) Series
Radford et al., 2018-2020
We express gratitude for the GPT series, which leverages unsupervised pre-training on large corpora to generate human-like text.
Key Features:
Unidirectional Language Modeling: Predicts the next token given previous tokens . Objective Function:
Decoder-Only Transformer Architecture: Utilizes masked self-attention to prevent the model from attending to future tokens.
Significance: Demonstrated the capability of large language models to perform few-shot learning, adapting to new tasks with minimal task-specific data.
4. Variational Autoencoders (VAEs)
Kingma and Welling, 2013
We appreciate VAEs for introducing a probabilistic approach to autoencoders, enabling generative modeling of complex data distributions.
Key Components:
Encoder Network: Learns an approximate posterior .
Decoder Network: Reconstructs the input from latent variables , modeling .
Objective Function (Evidence Lower Bound – ELBO): where is typically a standard normal prior .
Significance: Provided a framework for unsupervised learning of latent representations and generative modeling.
5. Generative Adversarial Networks (GANs)
Goodfellow et al., 2014
We are thankful for GANs, which consist of two neural networks—a generator and a critic —competing in a minimax game.
Objective Function: where is the data distribution and is the prior over the latent space.
Significance: Enabled the generation of highly realistic synthetic data, impacting image synthesis, data augmentation, and more.
6. Deep Reinforcement Learning
Mnih et al., 2015; Silver et al., 2016
We give thanks for the combination of deep learning with reinforcement learning, leading to agents capable of performing complex tasks.
Key Algorithms:
Deep Q-Networks (DQN): Approximate the action-value function using neural networks. Bellman Equation: where are the parameters of a target network.
Policy Gradient Methods: Optimize the policy directly. REINFORCE Algorithm Objective: where is the cumulative reward.
Significance: Achieved human-level performance in games like Atari and Go, advancing AI in decision-making tasks.
7. Normalization Techniques
We are grateful for normalization techniques that have improved training stability and performance of deep networks.
Batch Normalization(Ioffe and Szegedy, 2015)Formula: where and are the batch mean and variance.
Layer Normalization(Ba et al., 2016)Formula: where and are computed over the features of a single sample.
Significance: Mitigated internal covariate shift, enabling faster and more reliable training.
8. Attention Mechanisms in Neural Networks
Bahdanau et al., 2014; Luong et al., 2015
We appreciate attention mechanisms for allowing models to focus on specific parts of the input when generating each output element.
Key Concepts:
Alignment Scores: Compute the relevance between encoder hidden states and decoder state . Common Score Functions:
Dot-product:
Additive (Bahdanau attention):
Context Vector: where the attention weights are computed as:
Significance: Enhanced performance in sequence-to-sequence tasks by allowing models to utilize information from all input positions.
9. Graph Neural Networks (GNNs)
Scarselli et al., 2009; Kipf and Welling, 2016
We are thankful for GNNs, which extend neural networks to graph-structured data, enabling the modeling of relational information.
Message Passing Framework:
Node Representation Update: where:
is the representation of node at layer .
is the set of neighbors of node .
and are learnable weight matrices.
is a nonlinear activation function.
Graph Convolutional Networks (GCNs): where:
is the adjacency matrix with added self-loops.
is the degree matrix of .
Significance: Enabled advancements in social network analysis, molecular chemistry, and recommendation systems.
10. Self-Supervised Learning and Contrastive Learning
He et al., 2020; Chen et al., 2020
We are grateful for self-supervised learning techniques that leverage unlabeled data by creating surrogate tasks.
Contrastive Learning Objective:
InfoNCE Loss: where:
and are representations of two augmented views of the same sample.
is the cosine similarity.
is a temperature parameter.
is an indicator function equal to 1 when .
Significance: Improved representation learning, leading to state-of-the-art results in computer vision tasks without requiring labeled data.
11. Differential Privacy in Machine Learning
Abadi et al., 2016
We give thanks for techniques that allow training models while preserving the privacy of individual data points.
Differential Privacy Guarantee:
Definition: A randomized algorithm provides -differential privacy if for all datasets and differing on one element, and all measurable subsets :
Noise Addition: Applies calibrated noise to gradients during training to ensure privacy.
Significance: Enabled the deployment of machine learning models in privacy-sensitive applications.
12. Federated Learning
McMahan et al., 2017
We are thankful for federated learning, which allows training models across multiple decentralized devices while keeping data localized.
Federated Averaging Algorithm:
Local Update: Each client updates model parameters using local data :
Global Aggregation: The server aggregates updates: where:
is the number of samples at client .
is the total number of samples across all clients.
Significance: Addressed privacy concerns and bandwidth limitations in distributed systems.
13. Neural Architecture Search (NAS)
Zoph and Le, 2016
We appreciate NAS for automating the design of neural network architectures using optimization algorithms.
Approaches:
Reinforcement Learning-Based NAS: Uses an RNN controller to generate architectures, trained to maximize expected validation accuracy.
Differentiable NAS (DARTS): Models the architecture search space as continuous, enabling gradient-based optimization. Objective Function: where is obtained by:
Significance: Reduced human effort in designing architectures, leading to efficient and high-performing models.
We are thankful for advancements in optimization algorithms that improved training efficiency.
Adam Optimizer(Kingma and Ba, 2014) Update Rules:, , , , where:
is the gradient at time step .
and are hyperparameters controlling the exponential decay rates.
is the learning rate.
is a small constant to prevent division by zero.
Significance: Improved optimization efficiency and convergence in training deep neural networks.
15. Diffusion Models for Generative Modeling
Ho et al., 2020; Song et al., 2020
We give thanks for diffusion models, which are generative models that learn data distributions by reversing a diffusion (noising) process.
Key Concepts:
Forward Diffusion Process: Gradually adds Gaussian noise to data over timesteps. Noising Schedule:
Reverse Process: Learns to denoise from back to . Objective Function: where:
is the noise added to the data.
is the model’s prediction of the noise at timestep .
Significance: Achieved state-of-the-art results in image generation, rivaling GANs without their training instability.
Give Thanks…
This Thanksgiving, let’s celebrate and express our gratitude for these groundbreaking contributions to machine learning. These technical advancements have not only pushed the boundaries of what’s possible but have also laid the foundation for future innovations that will continue to shape our world.
May we continue to build upon these foundations and contribute to the growing field of machine learning.
References
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is All You Need. Advances in Neural Information Processing Systems. arXiv:1706.03762
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pre-training. OpenAI Blog.
Kingma, D. P., & Welling, M. (2013). Auto-Encoding Variational Bayes. arXiv:1312.6114
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative Adversarial Nets. Advances in Neural Information Processing Systems.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., & Hassabis, D. (2015). Human-level Control through Deep Reinforcement Learning. Nature.
Ioffe, S., & Szegedy, C. (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. International Conference on Machine Learning (ICML).
Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016). Layer Normalization. arXiv:1607.06450
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate. arXiv:1409.0473
Kipf, T. N., & Welling, M. (2016). Semi-Supervised Classification with Graph Convolutional Networks. arXiv:1609.02907
He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum Contrast for Unsupervised Visual Representation Learning. arXiv:1911.05722
Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B., Mironov, I., Talwar, K., & Zhang, L. (2016). Deep Learning with Differential Privacy. ACM SIGSAC Conference on Computer and Communications Security.
McMahan, B., Moore, E., Ramage, D., Hampson, S., & y Arcas, B. A. (2017). Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv:1602.05629
Zoph, B., & Le, Q. V. (2016). Neural Architecture Search with Reinforcement Learning. arXiv:1611.01578
Kingma, D. P., & Ba, J. (2014). Adam: A Method for Stochastic Optimization. arXiv:1412.6980
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. arXiv:2006.11239
Artificial intelligence (AI) is now embedded in everyday life, from self-driving cars to medical diagnostic tools, enabling tasks to be performed faster and, in some cases, more accurately than humans. However, this rapid advancement comes with significant challenges, particularly in the form of adversarial attacks. These attacks exploit small, often imperceptible changes in input data to deceive AI systems into making incorrect decisions. For example, a strategically placed sticker on a stop sign might cause an AI-powered car to misinterpret it as a speed limit sign, creating potentially dangerous situations; another example can be small perturbations added to your dog’s picture, which can lead to state-of-the-art AI to confuse it with a cat:
The Role of ReLU and Its Limitations
The Rectified Linear Unit (ReLU) activation function is a foundational component of many AI models. Its simplicity and efficiency have made it a go-to choice for training deep learning networks. However, ReLU’s unrestricted output can make models vulnerable to adversarial noise, leading to cascading errors in predictions. Attempts to address this vulnerability, such as Static-Max-Value ReLU (S-ReLU or capped ReLU), have introduced fixed output caps, but these solutions often underperform on more complex datasets and tasks.
Introducing D-ReLU
D-ReLU represents a significant advancement over traditional ReLU. It incorporates a dynamic output cap that adjusts based on the data flowing through the network. This adaptability serves as a robust defense mechanism against adversarial inputs while maintaining computational efficiency. In essence, D-ReLU acts as a self-adjusting safeguard, preserving model integrity even under duress.
Key Features of D-ReLU:
Adaptive Output Limits: D-ReLU employs learnable caps that evolve during training, enabling models to balance robustness and accuracy effectively.
Enhanced Resilience: D-ReLU has demonstrated superior performance against adversarial attacks, including FGSM, PGD, and Carlini-Wagner, while maintaining consistent performance on standard datasets.
Scalability: Tested on large-scale datasets like CIFAR-10, CIFAR-100, and TinyImagenet, D-ReLU has proven its ability to scale effectively without degradation in performance.
Efficient Training: Unlike adversarial training methods, which require extensive additional computations, D-ReLU achieves robustness naturally, streamlining the training process.
Real-World Viability: D-ReLU excels in real-world scenarios, including black-box attack settings where attackers lack full knowledge of the model.
The Broader Implications
In applications where reliability and safety are paramount—such as autonomous vehicles, financial systems, and medical imaging—D-ReLU offers a compelling solution to the challenges posed by adversarial inputs. By enhancing a model’s resilience without sacrificing performance, D-ReLU provides a vital upgrade for AI systems operating in high-stakes environments.
Future Directions
The potential of D-ReLU extends beyond current implementations. Areas of exploration include:
Further optimization for improved performance,
Applications in natural language processing and audio tasks,
Integration with complementary robust training methods for enhanced results.
For a detailed analysis and technical insights, download our paper here. If you are working on AI models, we encourage you to experiment with D-ReLU and share your experiences:
Sooksatra, Korn, and Pablo Rivas. 2024. “Dynamic-Max-Value ReLU Functions for Adversarially Robust Machine Learning Models” Mathematics 12, no. 22: 3551. https://doi.org/10.3390/math12223551
About the Author
Korn Sooksatra is a Ph.D. student at Baylor University, specializing in adversarial machine learning and AI robustness.
How can we improve the adversarial robustness of Vision Language Models (VLMs) to ensure their safe deployment in critical applications? This question drives our exploration into focused adversarial training techniques that improve the security of these models without excessive computational costs.
Adversarial Robustness and AI Safety
Adversarial attacks involve subtle manipulations of input data designed to deceive machine learning models into making incorrect predictions. In the context of VLMs, these attacks can have severe implications, especially when these models are deployed in sensitive areas such as autonomous driving, healthcare, and content moderation.
Enhancing the adversarial robustness of VLMs is crucial for AI safety. Robust models can withstand adversarial inputs, ensuring reliable performance and preventing malicious exploitation. Our research focuses on a novel approach to achieve this robustness by selectively re-training components of the multimodal architecture.
Our Approach
Traditional methods to improve model robustness often involve adversarial training, which integrates adversarial examples into the training process. However, this can be computationally intensive, particularly for complex models like VLMs that process images and text.
Our study introduces a more efficient strategy: adversarially re-training only the language model component of the VLM. This targeted approach leverages the Fast Gradient Sign Method (FGSM) to generate adversarial examples and incorporates them into the training of the text decoder. We maintain computational efficiency by keeping the image encoder fixed while significantly enhancing the model’s overall robustness.
Key Findings
Adversarial Training Efficiency: Adversarially re-training only the language model yields robustness comparable to full adversarial training, with reduced computational demands.
Selective Training Impact: Freezing the image encoder and focusing on the text decoder maintains high performance and robustness. In contrast, training only the image encoder results in a significant performance drop.
Benchmark Results: Experiments on the Flickr8k and COCO datasets demonstrate that our selective adversarial training approach effectively mitigates the impact of adversarial attacks, as evidenced by improved BLEU scores and model performance under adversarial conditions.
Implications for Ethical AI
Our findings support the development of more robust and secure AI systems, which is crucial for ethical AI deployment. By focusing on adversarial robustness, we contribute to the broader goal of AI safety, ensuring that multimodal models can be trusted in real-world applications.
Rashid, M.B., & Rivas, P. (2024). AI Safety in Practice: Enhancing Adversarial Robustness in Multimodal Image Captioning. 3rd Workshop on Ethical Artificial Intelligence: Methods and Applications, ACM SIGKDD’24. https://arxiv.org/abs/2407.21174
About the Author
Maisha Binte Rashid is a Ph.D. student at Baylor University, specializing in AI safety and multimodal machine learning.
The black market for stolen car parts is a significant problem, exacerbated by the rise of online marketplaces like Craigslist or OfferUp, where stolen goods are often sold under the radar. In response to this growing issue, our research team at Baylor University has been leveraging cutting-edge AI techniques to detect patterns in car part sales that could signal illicit activity. This work is part of the NSF-funded Research Experiences for Undergraduates (REU) program, which provides undergraduate students with hands-on research experience in critical areas like artificial intelligence. Our project, supported by NSF Grant #2210091, investigates the potential of deep learning models to analyze vast amounts of data from online listings, offering a new tool in the fight against stolen car parts.
Why This Research Matters
The theft and resale of car parts not only affect vehicle owners but also contribute to organized crime. Detecting patterns in how stolen parts are sold online can help law enforcement track and dismantle these criminal networks. This project also presents a unique challenge to the AI research community: the complexity of analyzing unstructured, noisy data from real-world platforms. By utilizing the Vision Transformer (ViT) for image analysis, our research offers a different approach compared to previous works that employed multimodal models like ImageBind and OpenFlamingo.
Dataset and Embedding Extraction
Our dataset comprises thousands of car parts advertisements scraped from Craigslist and OfferUp, each including images and textual descriptions. To process the image data, we used the Vision Transformer (ViT), a model pre-trained on ImageNet-21k. ViT processes images by splitting them into 16×16-pixel patches, allowing for the extraction of key features from each image. These features were converted into embeddings—high-dimensional vectors that represent each image’s content in a form that the model can analyze.
We extracted embeddings for nearly 85,000 images, which were then compiled into a CSV file for further analysis, including clustering and visualization. Unlike prior works by Hamara & Rivas (2024) and Rashid & Rivas (2024), which utilized multimodal models like ImageBind and OpenFlamingo to fuse image and text data, we focused solely on image embeddings in this phase to assess the effectiveness of ViT in capturing visual patterns related to illicit activities.
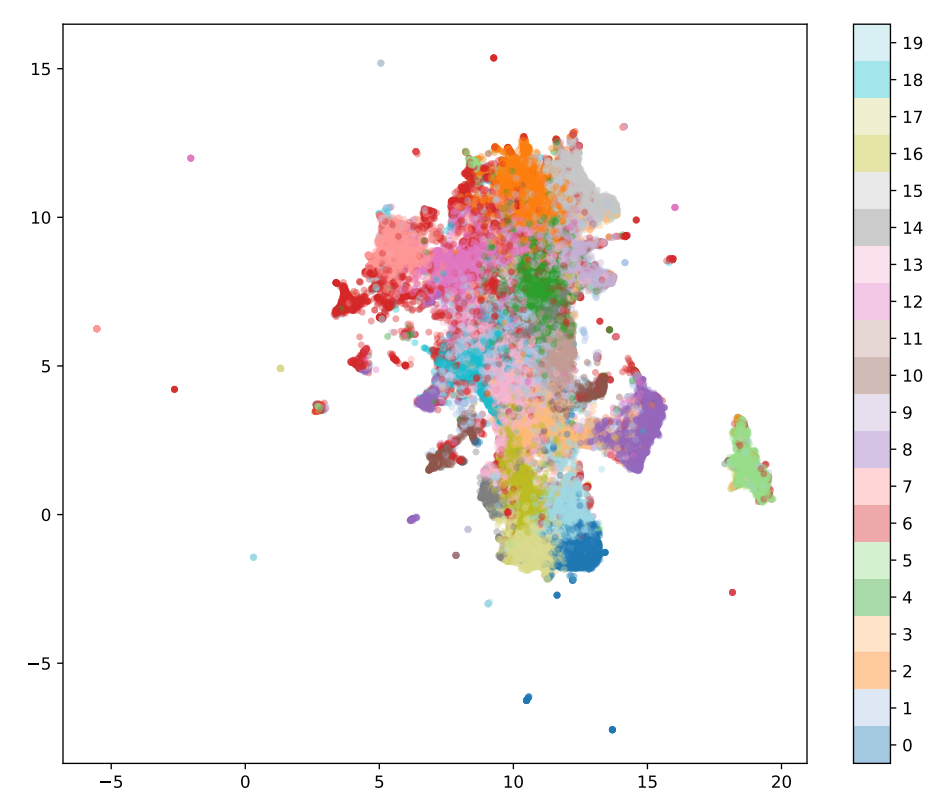
Clustering and Evaluation
With the embeddings extracted, we used UMAP (Uniform Manifold Approximation and Projection) to project the high-dimensional data into a more interpretable 2D space for visualization. We then applied K-Means clustering, a widely used algorithm for grouping data, and experimented with different embedding dimensions—16, 32, 64, and 128—to identify the optimal number of clusters.
Among these, 64 dimensions proved to be the best suited for our dataset, as determined by three key clustering performance metrics:
Silhouette Score: Measures how similar an object is to its own cluster compared to other clusters. A value of 0.015 indicated that some clusters were poorly defined.
Calinski-Harabasz Index: Evaluates the variance ratio between clusters versus within clusters.
Davies-Bouldin Index: Measures the average similarity between each cluster and its most similar cluster.
Although 128 dimensions performed well in some tests, 64 dimensions provided the clearest balance between cluster purity and computational efficiency. The low silhouette score, while indicating some overlap between clusters, helped confirm that most clusters were well-defined, despite several outliers—posts that displayed mixed or unclear features, such as images showing both powertrains and vehicle exteriors.
Findings and Analysis
Using the K-Means algorithm, we identified 20 distinct clusters, each representing different categories of car parts. Here are some key findings:
Cluster 0: Primarily contained exterior shots of full vehicles.
Cluster 1: Featured exterior components like mirrors and bumpers.
Cluster 2: Focused on powertrain parts such as engines and transmissions.
Cluster 3: Showcased body panels including doors, trunks, and hoods.
Cluster 4: Grouped images of towing accessories like trailer hitches.
After clustering, we applied K-Nearest Neighbors (KNN) to identify the top 10 posts nearest to each cluster centroid, which allowed us to analyze representative posts and confirm the coherence of each cluster. Despite the general success of this approach, outliers emerged in the UMAP visualization, indicating the need for further refinement to handle posts with mixed features. This challenge is common in image analysis, particularly when models rely solely on visual data without the contextual information that multimodal models can provide.
UMAP Visualization for 64 dimensions
Comparative Analysis with Prior Work
Our approach contrasts with that of Hamara & Rivas (2024) and Rashid & Rivas (2024), who utilized multimodal models like ImageBind and OpenFlamingo to integrate image and text data for enhanced analysis. While their methods leveraged the fusion of multiple data types to capture richer context, we aimed to assess the capabilities of ViT in isolating visual patterns indicative of illicit activity. This comparison highlights the trade-offs between focusing on single-modality models versus multimodal approaches in detecting complex patterns within unstructured data.
Broader Impact
This research demonstrates the potential of AI in analyzing large, unstructured datasets from online marketplaces, providing law enforcement with new tools to monitor and track stolen car parts. From a technical perspective, our project highlights the effectiveness of using ViT for image analysis in this context. As we continue refining our models and consider integrating multimodal approaches inspired by prior work, our collaboration with crosdisciplinary partners will ensure that this system becomes a valuable tool for combating the sale of stolen goods online.
As stated previously, the silhouette score for the dataset proved to be notably small, which was supported by the visualization containing numerous outliers. This may be attributed to clusters lacking clear definition, meaning that several posts contained images without many distinguishable features. This is understandable considering that while clusters emphasized a focus on specific car parts, many images still displayed various other vehicle components. For instance, although Cluster 2 primarily featured images of powertrains, the posts in this cluster also included shots of the exterior and body panels of the vehicle. This is logical as sellers often aim to showcase multiple facets of the vehicle when listing it, explaining the lack of focus on specific car parts.
About the Author
Cameron Armijo is a Computer Science undergraduate student at Baylor University, specializing in data mining.
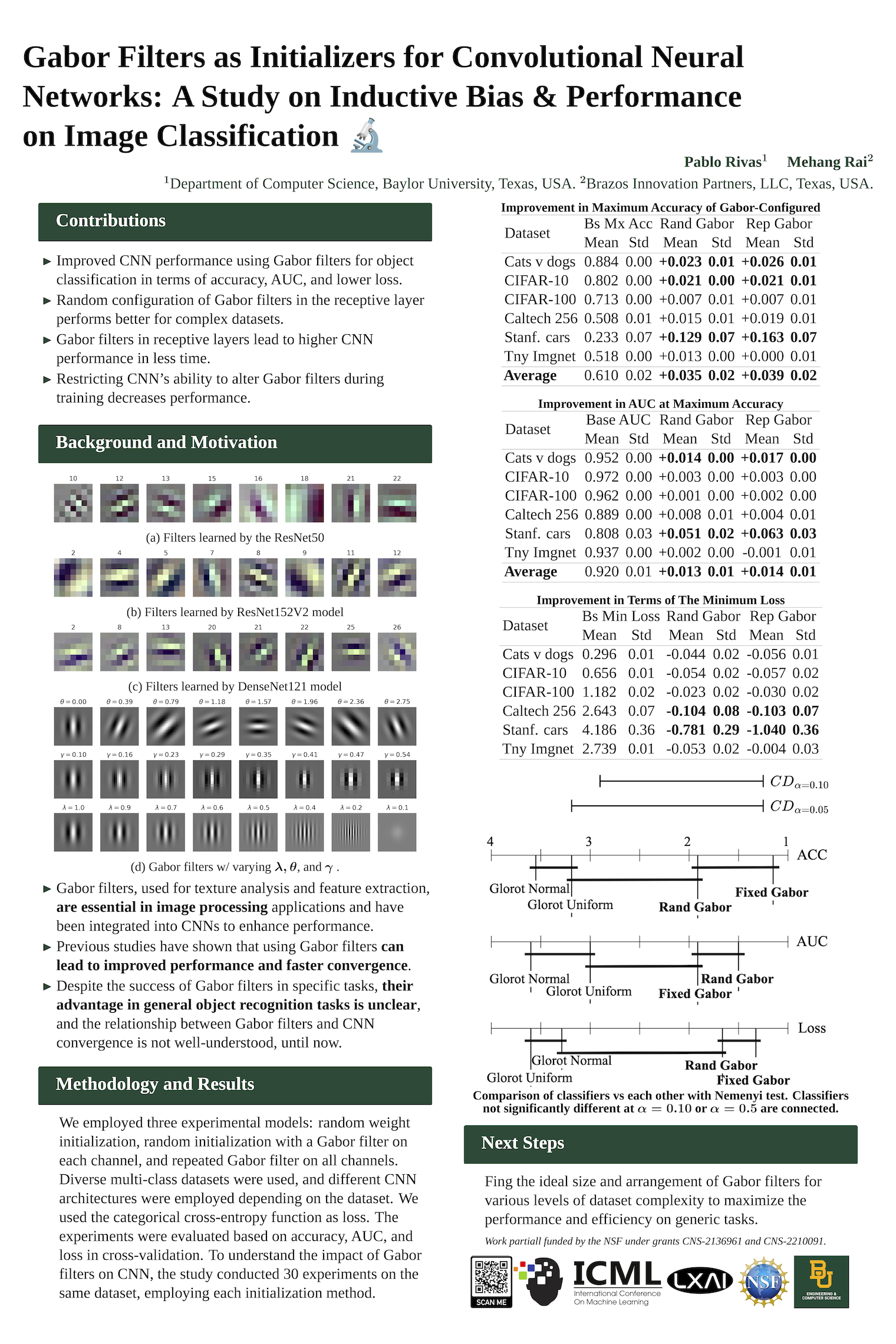
Rivas, Pablo, and Mehang Rai. 2023. “Enhancing CNNs Performance on Object Recognition Tasks with Gabor Initialization” Electronics 12, no. 19: 4072. https://doi.org/10.3390/electronics12194072
Our latest journal article, authored by Baylor graduate and former Baylor.AI lab member Mehang Rai, MS, marks an advancement in Convolutional Neural Networks (CNNs). The paper, titled “Enhancing CNNs Performance on Object Recognition Tasks with Gabor Initialization,” has not only garnered attention in academic circles but also achieved the prestigious Best Poster Award at the LXAI workshop at ICML 2023, a top-tier conference in the field.
Pablo Rivas and Mehang Rai, ” Gabor Filters as Initializers for Convolutional Neural Networks: A Study on Inductive Bias and Performance on Image Classification “, in The LXAI Workshop @ International Conference on Machine Learning (ICML 2023), 7/2023.
A Journey from Concept to Recognition Our journey with this research began with early discussions and progress shared here. The idea was simple yet profound: exploring the potential of Gabor filters, known for their exceptional feature extraction capabilities, in enhancing the performance of CNNs for object recognition tasks. This exploration led to a comprehensive study comparing the performance of Gabor-initialized CNNs against traditional CNNs with random initialization across six object recognition datasets.
Key Findings and Contributions The results were fascinating to us. The Gabor-initialized CNNs consistently outperformed traditional models in accuracy, area under the curve, minimum loss, and convergence speed. These findings provide robust evidence in favor of using Gabor-based methods for initializing the receptive fields of CNN architectures, a technique that was explored before with little success because researchers had been constraining Gabor filters during training, precluding gradient descent to optimize the filters as needed for general purpose object recognition, until now.
Our research contributes significantly to the field by demonstrating:
Improved performance in object classification tasks with Gabor-initialized CNNs.
Superior performance of random configurations of Gabor filters in the receptive layer, especially with complex datasets.
Enhanced performance of CNNs in a shorter time frame when incorporating Gabor filters.
Implications and Future Directions This study reaffirms the historical success of Gabor filters in image processing and opens new avenues for their application in modern CNN architectures. The impact of this research is vast, suggesting potential enhancements in various applications of CNNs, from medical imaging to autonomous vehicles.
As we celebrate this achievement, we also look forward to further research. Future studies could explore initializing other vision architectures, such as Vision Transformers (ViTs), with Gabor filters.
It’s a proud moment for us at the lab to see our research recognized on a global platform like ICML 2023 and published in a journal. This accomplishment is a testament to our commitment to pushing the boundaries of AI and ML research. We congratulate Mehang Rai for this remarkable achievement and thank the AI community for their continued support and recognition.
Baylor University has been awarded funding under the SaTC program for Enabling Interdisciplinary Collaboration; a grant led by Principal Investigator Dr. Pablo Rivas and an amazing group of multidisciplinary researchers formed by:
Dr. Gissella Bichler from California State University San Bernardino, Center for Criminal Justice Research, School of Criminology and Criminal Justice.
Dr. Tomas Cerny is at Baylor University in the Computer Science Department, leading software engineering research.
Dr. Laurie Giddens from the University of North Texas, a faculty member at the G. Brint Ryan College of Business.
Dr. Stacy Petter is at Wake Forest University in the School of Business. She and Dr. Giddens have extensive research and funding in human trafficking research.
Dr. Javier Turek, a Research Scientist in Machine Learning at Intel Labs, is our collaborator in matters related to machine learning for natural language processing.
This project was motivated by the increasing pattern of people buying and selling goods and services directly from other people via online marketplaces. While many online marketplaces enable transactions among reputable buyers and sellers, some platforms are vulnerable to suspicious transactions. This project investigates whether it is possible to automate the detection of illegal goods or services within online marketplaces. First, the project team will analyze the text of online advertisements and marketplace policies to identify indicators of suspicious activity. Then, the team will adapt the findings to a specific context to locate stolen motor vehicle parts advertised via online marketplaces. Together, the work will lead to general ways to identify signals of illegal online sales that can be used to help people choose trustworthy marketplaces and avoid illicit actors. This project will also provide law enforcement agencies and online marketplaces with insights to gather evidence on illicit goods or services on those marketplaces.
This research assesses the feasibility of modeling illegal activity in online consumer-to-consumer (C2C) platforms, using platform characteristics, seller profiles, and advertisements to prioritize investigations using actionable intelligence extracted from open-source information. The project is organized around three main steps. First, the research team will combine knowledge from computer science, criminology, and information systems to analyze online marketplace technology platform policies and identify platform features, policies, and terms of service that make platforms more vulnerable to criminal activity. Second, building on the understanding of platform vulnerabilities developed in the first step, the researchers will generate and train deep learning-based language models to detect illicit online commerce. Finally, to assess the generalizability of the identified markers, the investigators will apply the models to markets for motor vehicle parts, a licit marketplace that sometimes includes sellers offering stolen goods. This project establishes a cross-disciplinary partnership among a diverse group of researchers from different institutions and academic disciplines with collaborators from law enforcement and industry to develop practical, actionable insights.
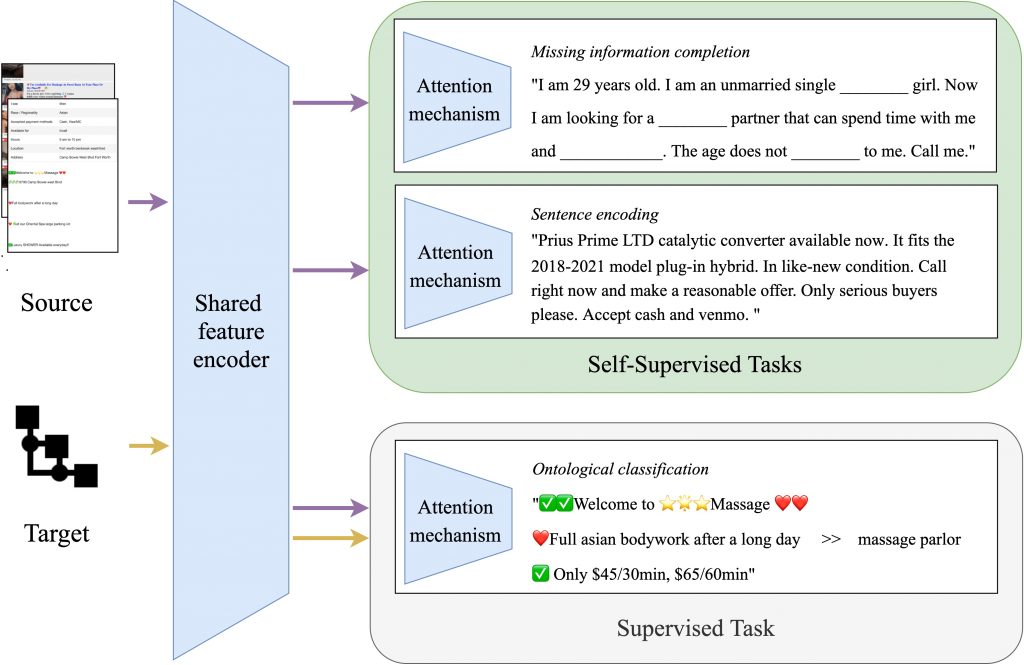
Self-supervised modeling. After providing a corpus associated with a C2C domain of interest and ontologies, we will extract features followed by attention mechanisms for self-supervised and supervised tasks. The self-supervised models include the completion of missing information and domain-specific text encoding for learning representations. Then supervised tasks will leverage these representations to learn the relationships with targets.

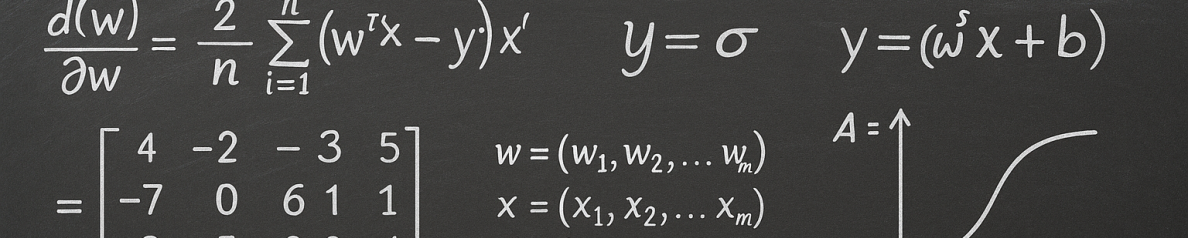

![\[\text{PSNR}=10\log_{10}\frac{\text{MAX}^2}{\text{MSE}}\]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-7898c1c1f5e8c4a261b8785f6d547dab_l3.png "Rendered by QuickLaTeX.com")

![\[L_{\text{WMSE}} = \frac{1}{\sum_i w_i}\sum_i w_i (y_i - \hat{y}_i)^2\]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-bdaf973c3a644f50ce284a270f9fcc1b_l3.png "Rendered by QuickLaTeX.com")
 to pixels with strong dust signatures, ensuring that the loss focuses on the most scientifically relevant portions of the scene.
to pixels with strong dust signatures, ensuring that the loss focuses on the most scientifically relevant portions of the scene. , which our theoretical analysis predicts will improve sample efficiency by roughly 30%. Future work will also incorporate self‑supervised pretraining on unlabeled MODIS sequences, and will test the pipeline on other aerosol phenomena such as smoke and volcanic ash.
, which our theoretical analysis predicts will improve sample efficiency by roughly 30%. Future work will also incorporate self‑supervised pretraining on unlabeled MODIS sequences, and will test the pipeline on other aerosol phenomena such as smoke and volcanic ash.



 where each head is computed as:
where each head is computed as: 

 where
where  is the set of masked positions.
is the set of masked positions. given previous tokens
given previous tokens  . Objective Function:
. Objective Function: 
 .
. , modeling
, modeling  .
.![\mathcal{L}(\theta, \phi; x) = -\text{KL}(q_{\phi}(z|x) \| p_{\theta}(z)) + \mathbb{E}_{q_{\phi}(z|x)}[\log p_{\theta}(x|z)]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-92d0f4d5005687fea92672cd46704072_l3.png "Rendered by QuickLaTeX.com") where
where  is typically a standard normal prior
is typically a standard normal prior  .
. and a critic
and a critic  —competing in a minimax game.
—competing in a minimax game.![\min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{data}}}[\log D(x)] + \mathbb{E}_{z \sim p_z}[\log(1 - D(G(z)))]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-f4c6097b521f4afe7b8923e542639fb8_l3.png "Rendered by QuickLaTeX.com") where
where  is the data distribution and
is the data distribution and  is the prior over the latent space.
is the prior over the latent space. using neural networks. Bellman Equation:
using neural networks. Bellman Equation:  where
where  are the parameters of a target network.
are the parameters of a target network. directly. REINFORCE Algorithm Objective:
directly. REINFORCE Algorithm Objective: ![\nabla_{\theta} J(\theta) = \mathbb{E}_{\pi_{\theta}} \left[ \nabla_{\theta} \log \pi_{\theta}(a|s) R \right]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-e53cb7a1cae29f8595a1b83926e92a7f_l3.png "Rendered by QuickLaTeX.com") where
where  is the cumulative reward.
is the cumulative reward. where
where  and
and  are the batch mean and variance.
are the batch mean and variance. where
where  and
and  are computed over the features of a single sample.
are computed over the features of a single sample. and decoder state
and decoder state  . Common Score Functions:
. Common Score Functions:

![\text{score}(h, s) = v_a^\top \tanh(W_a [h; s])](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-c1390492617640d0676cb7559ef2b7e6_l3.png "Rendered by QuickLaTeX.com")
 where the attention weights
where the attention weights  are computed as:
are computed as: 
 where:
where:
 is the representation of node
is the representation of node  at layer
at layer  .
. is the set of neighbors of node
is the set of neighbors of node  and
and  are learnable weight matrices.
are learnable weight matrices. is a nonlinear activation function.
is a nonlinear activation function. where:
where:
 is the adjacency matrix with added self-loops.
is the adjacency matrix with added self-loops. is the degree matrix of
is the degree matrix of  .
.![\mathcal{L}_{i,j} = -\log \frac{\exp(\text{sim}(z_i, z_j)/\tau)}{\sum_{k=1}^{2N} \textbf{1}_{[k \neq i]} \exp(\text{sim}(z_i, z_k)/\tau)}](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-6a9932a8dfe6978287a7781d76d979c1_l3.png "Rendered by QuickLaTeX.com") where:
where:
 and
and  are representations of two augmented views of the same sample.
are representations of two augmented views of the same sample. is the cosine similarity.
is the cosine similarity. is a temperature parameter.
is a temperature parameter.![\textbf{1}_{[k \neq i]}](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-bf75515a28c2f067b99872a895694ed8_l3.png "Rendered by QuickLaTeX.com") is an indicator function equal to 1 when
is an indicator function equal to 1 when  .
. provides
provides  -differential privacy if for all datasets
-differential privacy if for all datasets  differing on one element, and all measurable subsets
differing on one element, and all measurable subsets  :
: ![P[\mathcal{A}(D) \in S] \leq e^\epsilon P[\mathcal{A}(D') \in S] + \delta](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-fc3bfc99a2d0988d512d785abdbbe75c_l3.png "Rendered by QuickLaTeX.com")
 using local data
using local data  :
: 
 where:
where:
 is the number of samples at client
is the number of samples at client  is the total number of samples across all clients.
is the total number of samples across all clients. where
where  is obtained by:
is obtained by: 
 ,
,  ,
,  ,
,  ,
, 
 is the gradient at time step
is the gradient at time step  .
. and
and  are hyperparameters controlling the exponential decay rates.
are hyperparameters controlling the exponential decay rates. is the learning rate.
is the learning rate. is a small constant to prevent division by zero.
is a small constant to prevent division by zero. timesteps.
timesteps. 
 back to
back to  .
. ![\mathcal{L}_{\text{simple}} = \mathbb{E}_{t, x_0, \epsilon} \left[ \| \epsilon - \epsilon_\theta(x_t, t) \|^2 \right]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-ef4693d6547fa2ffa2c1970ed721c48e_l3.png "Rendered by QuickLaTeX.com") where:
where:
 is the model’s prediction of the noise at timestep
is the model’s prediction of the noise at timestep