We halve NeRF model size and cut training time by 35% using coreset‑driven neuron pruning, while keeping PSNR within 0.2 dB of the full model.
We examined three neuron‑pruning strategies for Neural Radiance Fields: uniform sampling, importance‑based pruning, and a coreset‑driven approach. Our experiments show that the coreset method reduces the MLP size by roughly 50 % and accelerates training by about one‑third, with only a minor loss in visual fidelity (PSNR drop of 0.2 dB).
TL;DR
Neuron‑level pruning can halve NeRF model size and speed up training by 35 %.
Our coreset method keeps PSNR at 21.3 dB vs. 21.5 dB for the full model.
The approach outperforms random uniform sampling and simple importance scores.
Why it matters
Neural Radiance Fields produce photorealistic 3D reconstructions, but their multilayer perceptrons (MLPs) are notoriously large and slow to train, often requiring days of GPU time. Reducing the computational footprint without sacrificing visual quality opens the door to real‑time applications, mobile deployment, and large‑scale scene generation. By exposing and exploiting latent sparsity in NeRF’s fully‑connected layers, we provide a practical pathway toward more efficient neural rendering pipelines.
How it works
We start from a standard NeRF MLP (256 × 256 neurons per hidden layer). For each neuron we compute two scores: the average magnitude of its incoming weights ( win ) and the average magnitude of its outgoing weights ( wout ). The outgoing score correlates more strongly with final rendering quality, so we prioritize neurons with higher wout. Using these scores we construct a coreset, a small, representative subset of neurons, that preserves the functional capacity of the original network. The selected neurons are then re‑wired into a compact MLP (e.g., 128 × 128 or 64 × 64), and the model is retrained from scratch. Uniform sampling simply drops neurons at random, while importance pruning drops those with the lowest wout or win scores; both are less informed than the coreset selection.
What we found
Across three benchmark scenes the coreset‑driven pruning consistently delivered the best trade‑off between efficiency and quality.
Model size shrank from 2.38 MB to 1.14 MB (≈ 50 % reduction). Parameters dropped from 595 K to 288 K.
Training time per 100 k iterations fell from 78.75 min to 51.25 min (≈ 35 % faster).
Peak signal‑to‑noise ratio decreased only from 21.5 dB to 21.3 dB (0.2 dB loss).
Uniform sampling to 64 × 64 neurons caused PSNR to plunge to 16.5 dB and model size to 0.7 MB, demonstrating that random removal is detrimental.
Importance pruning using wout preserved PSNR at 20.0 dB, better than using only win or the product of both.
Visual inspections confirmed that the coreset‑pruned models are indistinguishable from the full model in most viewpoints, while aggressive pruning shows only minor loss of fine detail.
Key equation
This converts the mean‑squared error between rendered and ground‑truth images into a decibel scale, allowing us to quantify the tiny fidelity loss introduced by pruning.
Limits and next steps
Our study focuses on static scenes and a single MLP architecture; performance on dynamic scenes or alternative NeRF variants remains untested. Moreover, we retrain the pruned network from scratch, which adds a brief warm‑up cost. Future work will explore layer‑wise pruning, integration with parameter‑efficient transfer learning, and joint optimization of pruning and quantization to push efficiency even further.
FAQ
Does pruning affect rendering speed at inference time?
Yes, a smaller MLP evaluates faster, typically yielding a modest inference‑time gain in addition to the training speedup.
Can we prune beyond 128 × 128 neurons?
We observed noticeable PSNR drops (≈ 1 dB) when compressing to 64 × 64, so deeper compression is possible but requires application‑specific quality tolerances.
Read the paper
Ding, T. K., Xiang, D., Rivas, P., & Dong, L. (2025). Neural pruning for 3D scene reconstruction: Efficient NeRF acceleration. In Proceedings of AIR-RES 2025: The 2025 International Conference on the AI Revolution: Research, Ethics, and Society (pp. 1–13). Las Vegas, NV, USA.
We present a comprehensive overview of the rapid progress in legal NLP, its systematic organization, and the pathways we see for future research.
A detailed survey of legal NLP advances, taxonomy of methods, and future research directions.This survey maps hundreds of recent studies onto a clear taxonomy of tasks, methods, word embeddings, and pre‑trained language models (PLMs) used for legal documents, and highlights the most effective pairings as well as the gaps that still need attention.
TL;DR
We reviewed a large body of literature that covers multiclass classification, summarization, information extraction, question answering, and coreference resolution in legal texts.
All papers agree on a taxonomy that links traditional machine‑learning methods, deep‑learning architectures, and transformer‑based PLMs to specific legal document types.
Our synthesis shows that domain‑adapted PLMs (e.g., Legal‑BERT, Longformer, BigBird) consistently outperform generic models, especially on long documents.
Key gaps remain in coreference resolution and specialised domains such as tax law and patent analysis.
Why it matters
Legal texts are dense, highly structured, and often lengthy. Automating their analysis improves efficiency, reduces human error, and makes legal information more accessible to practitioners, regulators, and the public. Across all inputs, authors stress that NLP has become essential for handling privacy policies, court records, patent filings, and other regulatory documents. By extracting and summarising relevant information, legal NLP directly supports faster decision‑making and broader access to justice.
How it works
We distilled the methodological landscape into five core steps that recur across the surveyed papers:
Task definition. Researchers first identify the legal NLP problem—classification, summarisation, extraction, question answering, or coreference resolution.
Data preparation. Legal corpora are collected (privacy policies, judgments, patents, tax rulings, etc.) and annotated using standard schemes.
Embedding selection. Word‑level embeddings such as Word2Vec or GloVe are combined with contextualised embeddings from PLMs.
Model choice. Traditional machine‑learning models (SVM, Naïve Bayes) and deep‑learning architectures (CNN, LSTM, BiLSTM‑CRF) are evaluated alongside transformer‑based PLMs (BERT, RoBERTa, Longformer, BigBird, SpanBERT).
Evaluation & fine‑tuning. Performance is measured on task‑specific metrics; domain‑adapted PLMs are often further pre‑trained on legal corpora before fine‑tuning.
This workflow appears consistently in the literature and provides a reproducible blueprint for new legal NLP projects.
What we found
Our synthesis highlights several recurring findings:
Comprehensive taxonomy. All sources agree on a systematic mapping of methods, embeddings, and PLMs to five principal legal tasks.
Transformer dominance. Transformer‑based PLMs, especially BERT variants, are the most frequently used models across tasks, showing strong gains over traditional machine‑learning baselines.
Long‑document handling. Architectures designed for extended context windows (Longformer, BigBird) consistently outperform standard BERT when processing lengthy legal texts.
Domain adaptation pays off. Custom legal versions of PLMs (Legal‑BERT, Custom LegalBERT) repeatedly demonstrate higher accuracy on classification, extraction, and question‑answering tasks.
Benchmarking efforts. Several inputs describe unified benchmarking frameworks that compare dozens of model‑embedding‑document combinations, providing community resources for reproducibility.
Understudied areas. Coreference resolution and specialised domains such as tax law receive relatively little attention, indicating clear research gaps.
Limits and next steps
While the surveyed work demonstrates impressive progress, common limitations emerge:
Interpretability. Many high‑performing models are black‑box transformers, raising concerns for compliance‑sensitive legal applications.
Resource demands. Large transformer models require substantial computational resources; lighter alternatives (DistilBERT, FastText) are explored, but often sacrifice some accuracy.
Data scarcity in niche domains. Certain legal sub‑fields (e.g., tax law, patent clause analysis) lack large, publicly available annotated datasets.
Future research in our community should therefore focus on:
Developing more interpretable, domain‑specific architectures.
Extending multilingual and multimodal capabilities to cover diverse jurisdictions.
Creating benchmark datasets for underrepresented tasks, such as coreference resolution.
Designing efficient training pipelines that balance performance with computational cost.
FAQ
What are the main legal NLP tasks covered?
Multiclass classification, summarisation, information extraction, question answering & information retrieval, and coreference resolution.
Which model families are most commonly used?
Traditional classifiers (SVM, CNN, LSTM) and transformer‑based PLMs such as BERT, RoBERTa, Longformer, BigBird, and specialised variants like Legal‑BERT.
Do transformer models handle long legal documents?
Yes. Longformer and BigBird are repeatedly cited as more effective for lengthy texts because they can process longer token windows.
Is domain‑specific pre‑training important?
All sources agree that adapting PLMs with legal corpora (custom legal embeddings) consistently improves performance across tasks.
What are the biggest open challenges?
Improving coreference resolution, expanding coverage to niche legal domains, and enhancing model interpretability while keeping resource use manageable.
Read the paper
For the full details of our analysis, please consult the original article.
Quevedo, E., Cerny, T., Rodriguez, A., Rivas, P., Yero, J., Sooksatra, K., Zhakubayev, A., & Taibi, D. (2023). Legal Natural Language Processing from 2015-2022: A Comprehensive Systematic Mapping Study of Advances and Applications. IEEE Access, 1–36. http://doi.org/10.1109/ACCESS.2023.3333946
We introduce a quanvolutional autoencoder that matches classical CNN performance on DDoS data while converging faster and offering greater training stability.
Our lab presents a quantum‑enhanced autoencoder that uses randomized 16‑qubit circuits to extract features from DDoS time‑series data. The architecture achieves comparable visualisation quality to classical convolutional networks, learns with markedly faster convergence, and shows reduced variance across training runs, opening a practical pathway for quantum machine learning in cybersecurity.
TL;DR
We propose a quanvolutional autoencoder that leverages random quantum circuits for DDoS traffic representation.
The model reaches comparable visual performance to classical CNN autoencoders while converging noticeably faster and exhibiting higher training stability.
Our approach demonstrates a concrete quantum advantage for a real‑world cybersecurity task without requiring extensive quantum training.
Why it matters
Distributed denial‑of‑service (DDoS) attacks continue to threaten the stability of internet services worldwide, demanding ever‑more sophisticated detection and analysis tools. Classical deep‑learning pipelines have shown strong performance but often require large training budgets and can be sensitive to hyper‑parameter choices. Quantum computing promises parallelism and high‑dimensional feature spaces that can be harvested without full‑scale quantum training. Demonstrating that a modest 16‑qubit quantum layer can accelerate representation learning for DDoS data provides a tangible proof‑of‑concept that quantum machine learning can move from theory to practice in cybersecurity.
How it works
Our method proceeds in three clear steps:
Random quantum feature extraction: We encode each time‑series slice of DDoS traffic into a 16‑qubit register and apply a randomly generated quantum circuit (the “quanvolutional filter”). Measurement outcomes produce a high‑dimensional classical vector that captures quantum‑enhanced correlations.
Autoencoding stage: The quantum‑derived vectors feed into a conventional autoencoder architecture (convolutional encoder‑decoder). The network learns to compress the data into a low‑dimensional latent space and reconstruct the original hive‑plot representation.
Training and evaluation: Because the quantum filters are fixed (non‑learnable), the only trainable parameters reside in the classical layers. Training proceeds with standard stochastic gradient descent, but the richer initial features lead to faster loss reduction and reduced variance across runs.
What we found
Experimental evaluation on publicly available DDoS hive‑plot datasets revealed three consistent outcomes across multiple runs:
Comparable visual quality: Reconstructed hive plots from the quantum model were indistinguishable from those produced by a baseline CNN autoencoder, confirming that quantum feature extraction does not degrade representation fidelity.
Faster convergence: The loss curve of the quanvolutional autoencoder descended to the target threshold in noticeably fewer epochs than the classical baseline, confirming accelerated learning dynamics.
Improved stability: Across ten independent training seeds, the quantum‑enhanced model displayed lower variance in final validation loss, indicating more reliable performance under different initialisations.
These findings collectively suggest that modest quantum circuits can provide a practical edge for unsupervised representation learning in a high‑stakes cybersecurity context.
Limits and next steps
While promising, our approach bears several limitations that we and the broader community should address:
Dataset specificity: Evaluation was confined to DDoS hive‑plot visualisations; broader network traffic formats may expose different challenges.
Fixed quantum filters: The non‑learnable nature of the random circuits simplifies training but may restrict adaptability to new attack patterns.
Quantum hardware constraints: Current simulations assume ideal gate operations; real devices introduce noise that can erode the observed advantage.
Future work will explore (i) applying the quanvolutional autoencoder to diverse cybersecurity datasets, (ii) integrating trainable quantum parametrisations to balance flexibility and overhead, and (iii) employing error‑mitigation and noise‑aware strategies so that the model remains robust on near‑term quantum processors.
FAQ
How does a random quantum circuit speed up learning?
Random quantum unitaries project classical inputs into a high‑dimensional Hilbert space, exposing correlations that are difficult for purely linear classical kernels. When these enriched vectors enter a trainable autoencoder, the network can locate informative latent directions with fewer optimization steps.
Do I need a full‑scale quantum computer to reproduce these results?
No. All experiments were run on classical simulators of a 16‑qubit system. The same pipeline can be executed on emerging cloud‑based quantum‑processing services, albeit with modest overhead for state preparation and measurement.
Is the quantum advantage permanent or dataset‑dependent?
Our current evidence points to a task‑specific speedup. Generalising the advantage will require systematic studies across multiple traffic‑analysis problems and possibly larger qubit counts.
Can this model be integrated into existing IDS pipelines?
Yes. Because the quantum layer acts as a pre‑processor that outputs classical vectors, it can be slotted into any conventional deep‑learning pipeline without disrupting downstream components.
What hardware is required to run the quanvolutional filters?
At present we use state‑of‑the‑art quantum simulators on GPUs. When deployed on physical quantum processors, a 16‑qubit superconducting or trapped‑ion device with gate fidelities above 99 % would be sufficient.
Does the approach scale to larger quantum devices?
Increasing qubit count can enrich feature expressivity but also raises circuit depth and noise susceptibility. Scaling strategies such as hybrid‑learnable filters and shallow entanglement patterns are active research directions.
Is the model suitable for real‑time DDoS detection?
Our current implementation focuses on representation learning rather than real‑time classification. Coupling the learned latent space with downstream classifiers is a natural extension toward live detection.
Read the paper
For the full technical description, experimental setup, and detailed discussion, consult the peer‑reviewed article linked below.
Rivas, P., Orduz, J., Jui, T. D., DeCusatis, C., & Khanal, B. (2024). Quantum‑Enhanced Representation Learning: A Quanvolutional Autoencoder Approach against DDoS Threats. Machine Learning and Knowledge Extraction, 6(2), 944–964. MDPI. https://doi.org/10.3390/make6020044
We review 88 multimodal ML papers, highlighting BERT and ResNet for text‑image tasks, fusion methods, and challenges like noise and adversarial attacks.
We systematically surveyed the literature to identify the most common pre‑trained models, fusion strategies, and open challenges when combining text and images in machine learning pipelines.
TL;DR
We reviewed 88 multimodal machine‑learning papers to map the current landscape.
BERT for text and ResNet (or VGG) for images dominate feature extraction.
Simple concatenation remains common, but attention‑based fusion is gaining traction.
Why it matters
Text and images together encode richer semantic information than either modality alone. Harnessing both can improve content understanding, recommendation systems, and decision‑making across domains such as healthcare, social media, and autonomous robotics. However, integrating these signals introduces new sources of noise and vulnerability that must be addressed for reliable deployment.
How it works (plain words)
Our workflow follows three clear steps:
Gather and filter the literature – we started from 341 retrieved papers and applied inclusion criteria to focus on 88 high‑impact studies.
Extract methodological details – for each study we recorded the pre‑trained language model (most often BERT or LSTM), the vision model (ResNet, VGG, or other CNNs), and the fusion approach (concatenation, early fusion, attention, or advanced neural networks).
Synthesise findings – we counted how frequently each component appears, noted emerging trends, and listed the recurring limitations reported by authors.
What we found
Feature extraction
We observed that BERT is the most frequently cited language encoder because of its strong contextual representations across a wide range of tasks.
For visual features, ResNet is the leading architecture, with VGG also appearing regularly in older studies.
Fusion strategies
Concatenation – a straightforward method that simply stacks the text and image embeddings – is still the baseline choice in many applications.
Attention mechanisms – either self‑attention within a joint transformer or cross‑modal attention linking BERT and ResNet embeddings – are increasingly adopted to let the model weigh the most informative signals.
More complex neural‑network‑based fusions (e.g., graph‑convolutional networks, GAN‑assisted approaches) are reported in emerging studies, especially when robustness to adversarial perturbations is a priority.
Challenges reported across the surveyed papers
Noisy or mislabeled data – label noise in either modality can degrade joint representations.
Adversarial attacks – malicious perturbations to either text or image streams can cause catastrophic mis‑predictions, and defensive techniques are still in early development.
Limits and next steps
Despite strong progress, several limitations persist:
Noisy data handling: Existing pipelines often rely on basic preprocessing; more sophisticated denoising or label‑noise‑robust training is needed.
Dataset size optimisation: Many studies use benchmark collections (Twitter, Flickr, COCO) but do not systematically explore the trade‑off between data volume and model complexity.
Adversarial robustness: Current defenses (e.g., auxiliary‑classifier GANs, conditional GANs, multimodal noise generators) are promising but lack thorough evaluation across diverse tasks.
Future work should therefore concentrate on three fronts: developing noise‑resilient preprocessing pipelines, designing scalable training regimes for limited multimodal datasets, and building provably robust fusion architectures that can withstand adversarial pressure.
FAQ
What pre‑trained models should we start with for a new text‑image project?
We recommend beginning with BERT (or its lightweight variants) for textual encoding and ResNet (or VGG) for visual encoding, as these models consistently achieve high baseline performance across the surveyed studies.
Is attention‑based fusion worth the added complexity?
Our review shows that attention mechanisms yield richer joint representations and improve performance on tasks requiring fine‑grained alignment (e.g., visual question answering). When computational resources allow, we suggest experimenting with cross‑modal attention after establishing a solid concatenation baseline.
Read the paper
Rashid, M. B., Rahaman, M. S., & Rivas, P. (2024, July). Navigating the Multimodal Landscape: A Review on Integration of Text and Image Data in Machine Learning Architectures. Machine Learning and Knowledge Extraction, 6(3), 1545–1563. https://doi.org/10.3390/make6030074Download PDF
We train a transformer encoder with supervised contrastive learning so that a 6‑ply beam search reaches 2593 Elo, rivaling Stockfish with far less computation.
We embed chess positions into a continuous space where distance mirrors evaluation. By moving toward an “advantage vector” in that space, our engine plans moves without deep tree search, delivering super‑human strength with a tiny search budget.
TL;DR
We replace deep tree search with planning in a learned latent space.
Our engine reaches an estimated 2593 Elo using only a 6‑ply beam search.
The approach is efficient, interpretable, and scales with model size.
Why it matters
Traditional chess engines such as Stockfish rely on exhaustive tree search that explores millions of positions and requires heavy hardware. Human grandmasters, by contrast, use intuition to prune the search space and then look ahead only a few moves. Replicating that human‑like intuition in an AI system could dramatically reduce the computational cost of strong play and make powerful chess agents accessible on modest devices. Moreover, a method that plans by moving through a learned representation is potentially transferable to any domain where a sensible state evaluation exists—games, robotics, or decision‑making problems.
How it works (plain words)
Our pipeline consists of three intuitive steps.
Learning the space. We train a transformer encoder on five million positions taken from the ChessBench dataset. Each position carries a Stockfish win‑probability. Using supervised contrastive learning, the model pulls together positions with similar probabilities and pushes apart those with different probabilities. The result is a high‑dimensional embedding where “nearby” boards have similar evaluations.
Defining an advantage direction. From the same training data we isolate extreme states: positions that Stockfish rates as forced checkmate for White (probability = 1.0) and for Black (probability = 0.0). We compute the mean embedding of each extreme set and subtract them. The resulting vector points from Black‑winning regions toward White‑winning regions and serves as our “advantage axis.”
Embedding‑guided beam search. At run time we enumerate all legal moves, embed each resulting board, and measure its cosine similarity to the advantage axis. The top‑k (k = 3) most aligned positions are kept and expanded recursively up to six plies. Because the score is purely geometric, the engine prefers moves that point in the direction of higher evaluation, effectively “walking” toward better regions of the space.
The entire process requires no hand‑crafted evaluation function and no recursive minimax or Monte‑Carlo tree search. Planning becomes a matter of geometric reasoning inside the embedding.
What we found
Elo performance
We evaluated two architectures:
Base model. 400 K training steps, 768‑dimensional embeddings, beam width = 3.
Small model. Same training regime but with fewer layers and a 512‑dimensional embedding.
When we increase the search depth from 2 to 6 plies, the Base model’s estimated Elo improves steadily: 2115 (2‑ply), 2318 (3‑ply), 2433 (4‑ply), 2538 (5‑ply), and 2593 (6‑ply). The Small model follows the same trend but stays roughly 30–50 points behind at every depth. The 2593 Elo estimate at depth 6 is comparable to Stockfish 16 running at a calibrated 2600 Elo, yet our engine performs the search on a single GPU in a fraction of the time.
Scaling behaviour
Both model size and embedding dimensionality contribute positively. Larger transformers (the Base configuration) consistently outperform the Small configuration, confirming that richer representations give the planner better navigation cues. Early experiments with higher‑dimensional embeddings (e.g., 1024 D) show modest additional gains, suggesting a ceiling that will likely rise with even bigger models.
Qualitative insights
We visualized thousands of positions using UMAP. The plot reveals a clear gradient: clusters of White‑advantage positions sit on one side, Black‑advantage positions on the opposite side, and balanced positions cluster near the origin. When we trace the embeddings of actual games, winning games trace smooth curves that move from the centre toward the appropriate advantage side, while tightly contested games jitter around the centre. These trajectories give us a visual proof that the embedding captures strategic progress without any explicit evaluation function.
Interpretability
Because move choice is a cosine similarity score, we can inspect why a move was preferred. For any position we can project its embedding onto the advantage axis and see whether the engine is pushing toward White‑dominant or Black‑dominant regions. This geometric view is far more transparent than a black‑box evaluation network that outputs a scalar score.
Key equation
Here, is the embedding of the i‑th board state, denotes the set of positives (positions whose Stockfish evaluations differ by less than the margin = 0.05), is the full batch, and is the temperature parameter. This supervised contrastive loss pulls together positions with similar evaluations and pushes apart those with dissimilar evaluations, shaping the latent space for geometric planning.
Limits and next steps
Current limitations
Greedy beam search. With a beam width of three, the search cannot revise early commitments. Long‑term tactical ideas that require a temporary sacrifice can be missed.
Training target dependence. Our contrastive objective uses Stockfish evaluations as ground truth. While this provides high‑quality numerical signals, it may not capture the nuanced strategic preferences of human players.
Future directions
Replace the greedy beam with more exploratory strategies such as wider or non‑greedy beams, Monte Carlo rollouts, or hybrid search that combines latent scoring with occasional shallow alpha‑beta pruning.
Fine‑tune the embedding with reinforcement learning, allowing the engine to discover its own evaluation signal from self‑play rather than relying solely on Stockfish.
Scale the transformer to larger depth and width, and enrich the positive‑pair sampling (e.g., include mid‑game strategic motifs) to sharpen the advantage axis.
Apply the same representation‑based planning to other perfect‑information games (Go, Shogi, Hex) where a numeric evaluation can be generated.
FAQ
What is “latent‑space planning”?
It is the idea that an agent can decide which action to take by moving its internal representation toward a region associated with higher value, instead of exploring a combinatorial tree of future states.
Why use supervised contrastive learning instead of ordinary regression?
Contrastive learning directly shapes the geometry of the space: positions with similar evaluations become neighbours, while dissimilar positions are pushed apart. This geometric structure is essential for the cosine‑similarity scoring used in our search.
How does the “advantage vector” get computed?
We take the mean embedding of forced‑checkmate positions for White (p = 1.0) and the mean embedding of forced‑checkmate positions for Black (p = 0.0) and subtract the latter from the former. The resulting vector points from Black‑winning regions toward White‑winning regions.
Can this method replace Monte‑Carlo Tree Search (MCTS) in AlphaZero‑style agents?
Our results show that, for chess, a well‑structured latent space can achieve comparable strength with far shallower search. Whether it can fully replace MCTS in other domains remains an open research question, but the principle of geometric planning is compatible with hybrid designs that still retain some tree‑based refinement.
Is the engine limited to Stockfish‑derived data?
In its current form, yes; we use Stockfish win‑probabilities as supervision. Future work plans to incorporate human annotations or self‑play reinforcement signals to reduce this dependency.
Read the paper
For a complete technical description, training details, and additional visualizations, see our full paper:
If you prefer a direct download, the PDF is available here: Download PDF
Reference
Hamara, A., Hamerly, G., Rivas, P., & Freeman, A. C. (2025). Learning to plan via supervised contrastive learning and strategic interpolation: A chess case study. In Proceedings of the Second Workshop on Game AI Algorithms and Multi‑Agent Learning (GAAMAL) at IJCAI 2025 (pp. 1–7). Montreal, Canada.
As we gather around the table this Thanksgiving, it’s the perfect time to reflect on and express gratitude for the remarkable strides made in machine learning (ML) over recent years. These technical innovations have advanced the field and paved the way for countless applications that enhance our daily lives. Let’s check out some of the most influential ML architectures and algorithms for which we are thankful as a community.
1. The Transformer Architecture
Vaswani et al., 2017
We are grateful for the Transformer architecture, which revolutionized sequence modeling by introducing a novel attention mechanism, eliminating the reliance on recurrent neural networks (RNNs) for handling sequential data.
Key Components:
Self-Attention Mechanism: Computes representations of the input sequence by relating different positions via attention weights.
Multi-Head Attention: Allows the model to focus on different positions by projecting queries, keys, and values multiple times with different linear projections. where each head is computed as:
Positional Encoding: Adds information about the position of tokens in the sequence since the model lacks recurrence.
Significance: Enabled parallelization in sequence processing, leading to significant speed-ups and improved performance in tasks like machine translation and language modeling.
2. Bidirectional Encoder Representations from Transformers (BERT)
Devlin et al., 2018
We are thankful for BERT, which introduced a method for pre-training deep bidirectional representations by jointly conditioning on both left and right contexts in all layers.
Key Concepts:
Masked Language Modeling (MLM): Randomly masks tokens in the input and predicts them using the surrounding context. Loss Function: where is the set of masked positions.
Next Sentence Prediction (NSP): Predicts whether a given pair of sentences follows sequentially in the original text.
Significance: Achieved state-of-the-art results on a wide range of NLP tasks via fine-tuning, demonstrating the power of large-scale pre-training.
3. Generative Pre-trained Transformers (GPT) Series
Radford et al., 2018-2020
We express gratitude for the GPT series, which leverages unsupervised pre-training on large corpora to generate human-like text.
Key Features:
Unidirectional Language Modeling: Predicts the next token given previous tokens . Objective Function:
Decoder-Only Transformer Architecture: Utilizes masked self-attention to prevent the model from attending to future tokens.
Significance: Demonstrated the capability of large language models to perform few-shot learning, adapting to new tasks with minimal task-specific data.
4. Variational Autoencoders (VAEs)
Kingma and Welling, 2013
We appreciate VAEs for introducing a probabilistic approach to autoencoders, enabling generative modeling of complex data distributions.
Key Components:
Encoder Network: Learns an approximate posterior .
Decoder Network: Reconstructs the input from latent variables , modeling .
Objective Function (Evidence Lower Bound – ELBO): where is typically a standard normal prior .
Significance: Provided a framework for unsupervised learning of latent representations and generative modeling.
5. Generative Adversarial Networks (GANs)
Goodfellow et al., 2014
We are thankful for GANs, which consist of two neural networks—a generator and a critic —competing in a minimax game.
Objective Function: where is the data distribution and is the prior over the latent space.
Significance: Enabled the generation of highly realistic synthetic data, impacting image synthesis, data augmentation, and more.
6. Deep Reinforcement Learning
Mnih et al., 2015; Silver et al., 2016
We give thanks for the combination of deep learning with reinforcement learning, leading to agents capable of performing complex tasks.
Key Algorithms:
Deep Q-Networks (DQN): Approximate the action-value function using neural networks. Bellman Equation: where are the parameters of a target network.
Policy Gradient Methods: Optimize the policy directly. REINFORCE Algorithm Objective: where is the cumulative reward.
Significance: Achieved human-level performance in games like Atari and Go, advancing AI in decision-making tasks.
7. Normalization Techniques
We are grateful for normalization techniques that have improved training stability and performance of deep networks.
Batch Normalization(Ioffe and Szegedy, 2015)Formula: where and are the batch mean and variance.
Layer Normalization(Ba et al., 2016)Formula: where and are computed over the features of a single sample.
Significance: Mitigated internal covariate shift, enabling faster and more reliable training.
8. Attention Mechanisms in Neural Networks
Bahdanau et al., 2014; Luong et al., 2015
We appreciate attention mechanisms for allowing models to focus on specific parts of the input when generating each output element.
Key Concepts:
Alignment Scores: Compute the relevance between encoder hidden states and decoder state . Common Score Functions:
Dot-product:
Additive (Bahdanau attention):
Context Vector: where the attention weights are computed as:
Significance: Enhanced performance in sequence-to-sequence tasks by allowing models to utilize information from all input positions.
9. Graph Neural Networks (GNNs)
Scarselli et al., 2009; Kipf and Welling, 2016
We are thankful for GNNs, which extend neural networks to graph-structured data, enabling the modeling of relational information.
Message Passing Framework:
Node Representation Update: where:
is the representation of node at layer .
is the set of neighbors of node .
and are learnable weight matrices.
is a nonlinear activation function.
Graph Convolutional Networks (GCNs): where:
is the adjacency matrix with added self-loops.
is the degree matrix of .
Significance: Enabled advancements in social network analysis, molecular chemistry, and recommendation systems.
10. Self-Supervised Learning and Contrastive Learning
He et al., 2020; Chen et al., 2020
We are grateful for self-supervised learning techniques that leverage unlabeled data by creating surrogate tasks.
Contrastive Learning Objective:
InfoNCE Loss: where:
and are representations of two augmented views of the same sample.
is the cosine similarity.
is a temperature parameter.
is an indicator function equal to 1 when .
Significance: Improved representation learning, leading to state-of-the-art results in computer vision tasks without requiring labeled data.
11. Differential Privacy in Machine Learning
Abadi et al., 2016
We give thanks for techniques that allow training models while preserving the privacy of individual data points.
Differential Privacy Guarantee:
Definition: A randomized algorithm provides -differential privacy if for all datasets and differing on one element, and all measurable subsets :
Noise Addition: Applies calibrated noise to gradients during training to ensure privacy.
Significance: Enabled the deployment of machine learning models in privacy-sensitive applications.
12. Federated Learning
McMahan et al., 2017
We are thankful for federated learning, which allows training models across multiple decentralized devices while keeping data localized.
Federated Averaging Algorithm:
Local Update: Each client updates model parameters using local data :
Global Aggregation: The server aggregates updates: where:
is the number of samples at client .
is the total number of samples across all clients.
Significance: Addressed privacy concerns and bandwidth limitations in distributed systems.
13. Neural Architecture Search (NAS)
Zoph and Le, 2016
We appreciate NAS for automating the design of neural network architectures using optimization algorithms.
Approaches:
Reinforcement Learning-Based NAS: Uses an RNN controller to generate architectures, trained to maximize expected validation accuracy.
Differentiable NAS (DARTS): Models the architecture search space as continuous, enabling gradient-based optimization. Objective Function: where is obtained by:
Significance: Reduced human effort in designing architectures, leading to efficient and high-performing models.
We are thankful for advancements in optimization algorithms that improved training efficiency.
Adam Optimizer(Kingma and Ba, 2014) Update Rules:, , , , where:
is the gradient at time step .
and are hyperparameters controlling the exponential decay rates.
is the learning rate.
is a small constant to prevent division by zero.
Significance: Improved optimization efficiency and convergence in training deep neural networks.
15. Diffusion Models for Generative Modeling
Ho et al., 2020; Song et al., 2020
We give thanks for diffusion models, which are generative models that learn data distributions by reversing a diffusion (noising) process.
Key Concepts:
Forward Diffusion Process: Gradually adds Gaussian noise to data over timesteps. Noising Schedule:
Reverse Process: Learns to denoise from back to . Objective Function: where:
is the noise added to the data.
is the model’s prediction of the noise at timestep .
Significance: Achieved state-of-the-art results in image generation, rivaling GANs without their training instability.
Give Thanks…
This Thanksgiving, let’s celebrate and express our gratitude for these groundbreaking contributions to machine learning. These technical advancements have not only pushed the boundaries of what’s possible but have also laid the foundation for future innovations that will continue to shape our world.
May we continue to build upon these foundations and contribute to the growing field of machine learning.
References
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is All You Need. Advances in Neural Information Processing Systems. arXiv:1706.03762
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pre-training. OpenAI Blog.
Kingma, D. P., & Welling, M. (2013). Auto-Encoding Variational Bayes. arXiv:1312.6114
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative Adversarial Nets. Advances in Neural Information Processing Systems.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., & Hassabis, D. (2015). Human-level Control through Deep Reinforcement Learning. Nature.
Ioffe, S., & Szegedy, C. (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. International Conference on Machine Learning (ICML).
Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016). Layer Normalization. arXiv:1607.06450
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate. arXiv:1409.0473
Kipf, T. N., & Welling, M. (2016). Semi-Supervised Classification with Graph Convolutional Networks. arXiv:1609.02907
He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum Contrast for Unsupervised Visual Representation Learning. arXiv:1911.05722
Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B., Mironov, I., Talwar, K., & Zhang, L. (2016). Deep Learning with Differential Privacy. ACM SIGSAC Conference on Computer and Communications Security.
McMahan, B., Moore, E., Ramage, D., Hampson, S., & y Arcas, B. A. (2017). Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv:1602.05629
Zoph, B., & Le, Q. V. (2016). Neural Architecture Search with Reinforcement Learning. arXiv:1611.01578
Kingma, D. P., & Ba, J. (2014). Adam: A Method for Stochastic Optimization. arXiv:1412.6980
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. arXiv:2006.11239
Five years ago, a groundbreaking paper introduced DiPol-GAN, a generative adversarial network (GAN) designed to create molecular graphs with specific chemical properties. Authored by Michael Guarino, et al. in 2019, this work remains a testament to the ingenuity at the intersection of machine learning and computational chemistry. Let’s dive into its contributions and why it continues to be influential.
From Molecules to Meaning: DiPol-GAN’s Key Innovations
DiPol-GAN broke new ground by addressing the complexities of molecular graph generation—a task requiring precision and adherence to chemical constraints. Here are the standout elements of this innovative approach:
Direct Graph Representations While many models relied on SMILES strings to describe molecular structures, DiPol-GAN embraced the inherent richness of graph representations. Nodes represented atoms, edges captured bonds, and the graph structure preserved the relational nature of molecules—key for meaningful chemical property optimization.
Hierarchical Reasoning with DIFFPOOL The paper introduced the use of Differentiable Pooling (DIFFPOOL) in the GAN discriminator. DIFFPOOL hierarchically aggregated graph nodes, allowing the model to extract high-level features and improve classification performance. Moreover, the authors adapted DIFFPOOL to handle multi-relational graphs, capturing the nuances of bond types—an essential feature for molecular modeling.
Reinforcement Learning for Targeted Molecules DiPol-GAN incorporated a policy network to nudge the generative process toward molecules with desired properties, like solubility (logP) or drug-likeness. This clever integration of reinforcement learning allowed the model to focus on chemically relevant outcomes, setting a precedent for property-driven molecular design.
Five Years Later: Why DiPol-GAN Still Resonates
Even as research in graph neural networks and molecular AI progresses, DiPol-GAN’s contributions remain strikingly relevant:
Raising the Bar for Molecular GANs: By addressing the dual challenges of graph isomorphism and multi-relational edges, this model set a high standard for graph-based GANs.
Chemical Property Alignment: The integration of reinforcement learning into graph generation directly inspired modern approaches to property-targeted molecule design.
Benchmark Metrics: The study’s rigorous evaluation on validity, uniqueness, and novelty using the QM9 dataset provided benchmarks that still guide research today.
Continuing the Journey
DiPol-GAN’s legacy reminds us of the powerful synergy between machine learning and chemistry. Whether you’re exploring novel graph neural network architectures or advancing property-driven molecule generation, this paper offers invaluable insights.
For those working in related domains, revisiting this milestone study could spark new ideas and breakthroughs. Be sure to include it in your references to honor its influence and acknowledge the innovation it brought to the field:
Guarino, M., & Shah, A. Rivas, P., (2019). DiPol-GAN: Generating Molecular Graphs Adversarially with Relational Differentiable Pooling. Presented at the LXAI Workshop @ Neural Information Processing Society Conference (NeurIPS), pp. 9. [download]
Let’s keep building on this foundation, advancing science one molecule at a time.
The black market for stolen car parts is a significant problem, exacerbated by the rise of online marketplaces like Craigslist or OfferUp, where stolen goods are often sold under the radar. In response to this growing issue, our research team at Baylor University has been leveraging cutting-edge AI techniques to detect patterns in car part sales that could signal illicit activity. This work is part of the NSF-funded Research Experiences for Undergraduates (REU) program, which provides undergraduate students with hands-on research experience in critical areas like artificial intelligence. Our project, supported by NSF Grant #2210091, investigates the potential of deep learning models to analyze vast amounts of data from online listings, offering a new tool in the fight against stolen car parts.
Why This Research Matters
The theft and resale of car parts not only affect vehicle owners but also contribute to organized crime. Detecting patterns in how stolen parts are sold online can help law enforcement track and dismantle these criminal networks. This project also presents a unique challenge to the AI research community: the complexity of analyzing unstructured, noisy data from real-world platforms. By utilizing the Vision Transformer (ViT) for image analysis, our research offers a different approach compared to previous works that employed multimodal models like ImageBind and OpenFlamingo.
Dataset and Embedding Extraction
Our dataset comprises thousands of car parts advertisements scraped from Craigslist and OfferUp, each including images and textual descriptions. To process the image data, we used the Vision Transformer (ViT), a model pre-trained on ImageNet-21k. ViT processes images by splitting them into 16×16-pixel patches, allowing for the extraction of key features from each image. These features were converted into embeddings—high-dimensional vectors that represent each image’s content in a form that the model can analyze.
We extracted embeddings for nearly 85,000 images, which were then compiled into a CSV file for further analysis, including clustering and visualization. Unlike prior works by Hamara & Rivas (2024) and Rashid & Rivas (2024), which utilized multimodal models like ImageBind and OpenFlamingo to fuse image and text data, we focused solely on image embeddings in this phase to assess the effectiveness of ViT in capturing visual patterns related to illicit activities.
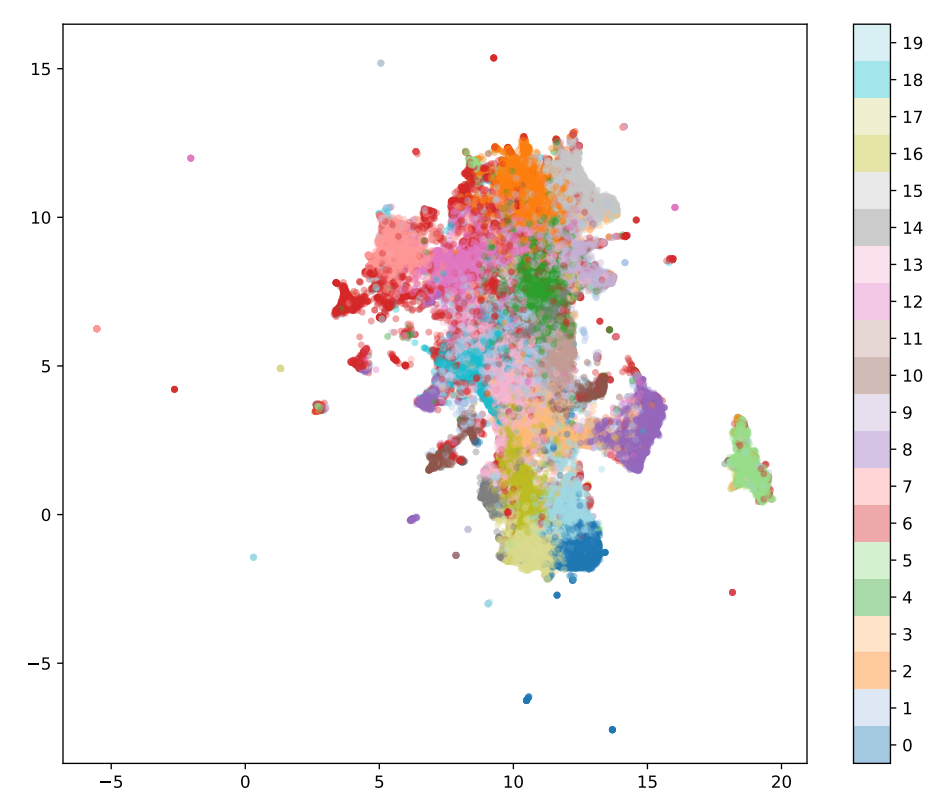
Clustering and Evaluation
With the embeddings extracted, we used UMAP (Uniform Manifold Approximation and Projection) to project the high-dimensional data into a more interpretable 2D space for visualization. We then applied K-Means clustering, a widely used algorithm for grouping data, and experimented with different embedding dimensions—16, 32, 64, and 128—to identify the optimal number of clusters.
Among these, 64 dimensions proved to be the best suited for our dataset, as determined by three key clustering performance metrics:
Silhouette Score: Measures how similar an object is to its own cluster compared to other clusters. A value of 0.015 indicated that some clusters were poorly defined.
Calinski-Harabasz Index: Evaluates the variance ratio between clusters versus within clusters.
Davies-Bouldin Index: Measures the average similarity between each cluster and its most similar cluster.
Although 128 dimensions performed well in some tests, 64 dimensions provided the clearest balance between cluster purity and computational efficiency. The low silhouette score, while indicating some overlap between clusters, helped confirm that most clusters were well-defined, despite several outliers—posts that displayed mixed or unclear features, such as images showing both powertrains and vehicle exteriors.
Findings and Analysis
Using the K-Means algorithm, we identified 20 distinct clusters, each representing different categories of car parts. Here are some key findings:
Cluster 0: Primarily contained exterior shots of full vehicles.
Cluster 1: Featured exterior components like mirrors and bumpers.
Cluster 2: Focused on powertrain parts such as engines and transmissions.
Cluster 3: Showcased body panels including doors, trunks, and hoods.
Cluster 4: Grouped images of towing accessories like trailer hitches.
After clustering, we applied K-Nearest Neighbors (KNN) to identify the top 10 posts nearest to each cluster centroid, which allowed us to analyze representative posts and confirm the coherence of each cluster. Despite the general success of this approach, outliers emerged in the UMAP visualization, indicating the need for further refinement to handle posts with mixed features. This challenge is common in image analysis, particularly when models rely solely on visual data without the contextual information that multimodal models can provide.
UMAP Visualization for 64 dimensions
Comparative Analysis with Prior Work
Our approach contrasts with that of Hamara & Rivas (2024) and Rashid & Rivas (2024), who utilized multimodal models like ImageBind and OpenFlamingo to integrate image and text data for enhanced analysis. While their methods leveraged the fusion of multiple data types to capture richer context, we aimed to assess the capabilities of ViT in isolating visual patterns indicative of illicit activity. This comparison highlights the trade-offs between focusing on single-modality models versus multimodal approaches in detecting complex patterns within unstructured data.
Broader Impact
This research demonstrates the potential of AI in analyzing large, unstructured datasets from online marketplaces, providing law enforcement with new tools to monitor and track stolen car parts. From a technical perspective, our project highlights the effectiveness of using ViT for image analysis in this context. As we continue refining our models and consider integrating multimodal approaches inspired by prior work, our collaboration with crosdisciplinary partners will ensure that this system becomes a valuable tool for combating the sale of stolen goods online.
As stated previously, the silhouette score for the dataset proved to be notably small, which was supported by the visualization containing numerous outliers. This may be attributed to clusters lacking clear definition, meaning that several posts contained images without many distinguishable features. This is understandable considering that while clusters emphasized a focus on specific car parts, many images still displayed various other vehicle components. For instance, although Cluster 2 primarily featured images of powertrains, the posts in this cluster also included shots of the exterior and body panels of the vehicle. This is logical as sellers often aim to showcase multiple facets of the vehicle when listing it, explaining the lack of focus on specific car parts.
About the Author
Cameron Armijo is a Computer Science undergraduate student at Baylor University, specializing in data mining.
Baylor University has been awarded funding under the SaTC program for Enabling Interdisciplinary Collaboration; a grant led by Principal Investigator Dr. Pablo Rivas and an amazing group of multidisciplinary researchers formed by:
Dr. Gissella Bichler from California State University San Bernardino, Center for Criminal Justice Research, School of Criminology and Criminal Justice.
Dr. Tomas Cerny is at Baylor University in the Computer Science Department, leading software engineering research.
Dr. Laurie Giddens from the University of North Texas, a faculty member at the G. Brint Ryan College of Business.
Dr. Stacy Petter is at Wake Forest University in the School of Business. She and Dr. Giddens have extensive research and funding in human trafficking research.
Dr. Javier Turek, a Research Scientist in Machine Learning at Intel Labs, is our collaborator in matters related to machine learning for natural language processing.
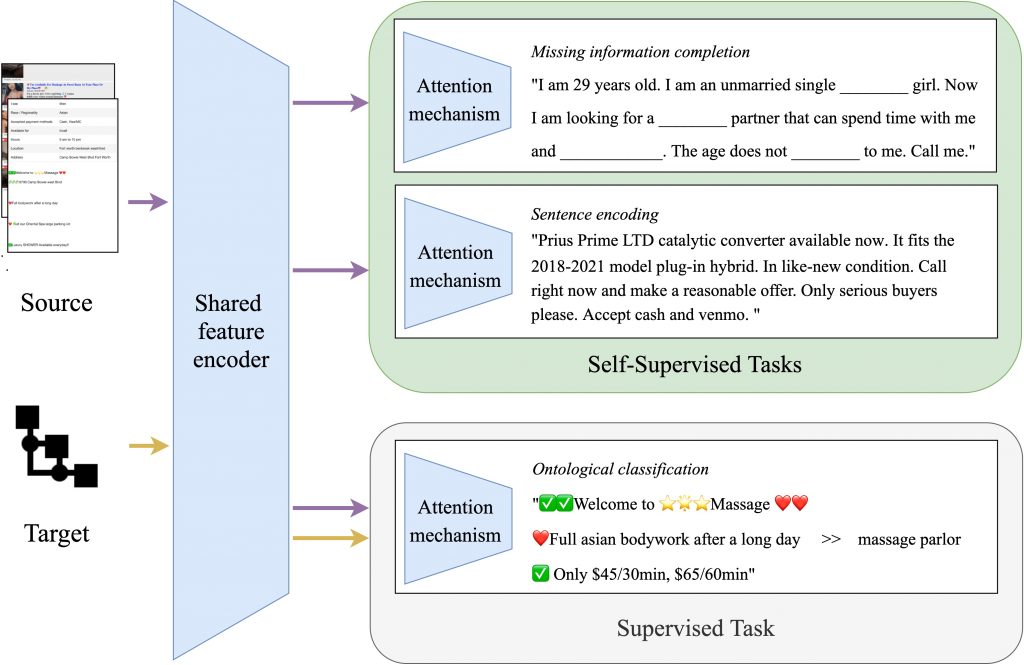
This project was motivated by the increasing pattern of people buying and selling goods and services directly from other people via online marketplaces. While many online marketplaces enable transactions among reputable buyers and sellers, some platforms are vulnerable to suspicious transactions. This project investigates whether it is possible to automate the detection of illegal goods or services within online marketplaces. First, the project team will analyze the text of online advertisements and marketplace policies to identify indicators of suspicious activity. Then, the team will adapt the findings to a specific context to locate stolen motor vehicle parts advertised via online marketplaces. Together, the work will lead to general ways to identify signals of illegal online sales that can be used to help people choose trustworthy marketplaces and avoid illicit actors. This project will also provide law enforcement agencies and online marketplaces with insights to gather evidence on illicit goods or services on those marketplaces.
This research assesses the feasibility of modeling illegal activity in online consumer-to-consumer (C2C) platforms, using platform characteristics, seller profiles, and advertisements to prioritize investigations using actionable intelligence extracted from open-source information. The project is organized around three main steps. First, the research team will combine knowledge from computer science, criminology, and information systems to analyze online marketplace technology platform policies and identify platform features, policies, and terms of service that make platforms more vulnerable to criminal activity. Second, building on the understanding of platform vulnerabilities developed in the first step, the researchers will generate and train deep learning-based language models to detect illicit online commerce. Finally, to assess the generalizability of the identified markers, the investigators will apply the models to markets for motor vehicle parts, a licit marketplace that sometimes includes sellers offering stolen goods. This project establishes a cross-disciplinary partnership among a diverse group of researchers from different institutions and academic disciplines with collaborators from law enforcement and industry to develop practical, actionable insights.
Self-supervised modeling. After providing a corpus associated with a C2C domain of interest and ontologies, we will extract features followed by attention mechanisms for self-supervised and supervised tasks. The self-supervised models include the completion of missing information and domain-specific text encoding for learning representations. Then supervised tasks will leverage these representations to learn the relationships with targets.
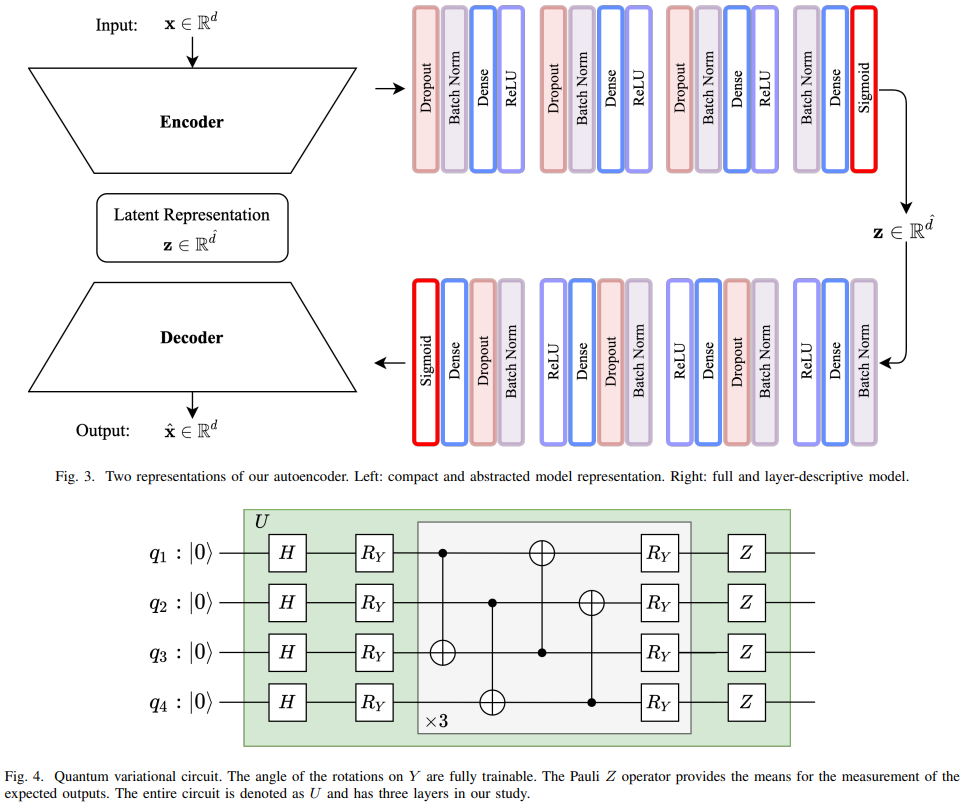
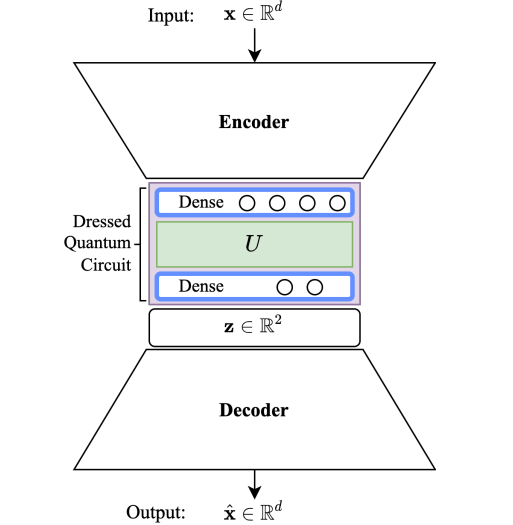
One of our recent papers introduces a novel hybrid quantum machine learning approach to unsupervised representation learning by using a quantum variational circuit that is trainable with traditional gradient descent techniques. Access it here: [ bib | .pdf ]
Much of the work related to quantum machine learning has been popularized in recent years. Some of the most notable efforts involve variational approaches (Cerezo 2021, Khoshaman 2018, Yuan 2019). Researchers have shown that these models are effective in complex tasks that grant further studies and open new doors for applied quantum machine learning research.
Another popular approach is to perform kernel learning using a quantum approach (Blank 2020, Schuld 2019, Rebentrost 2014). In this case the kernel-based projection of data produces a easible linear mapping to the desired target as follows:
(1)
for hyper parameters that need to be provided or learned. This enables the creation of some types of support vector machines whose kernels are calculated such that the data is processed in the quantum realm. That is . The work of Schuld et al., expands the theory behind this idea an show that all kernel methods can be quantum machine learning methods.
Recently, in 2020, Mari et al., worked on variational models that are hybrid in format. Particularly, the authors focused on transfer learning, i.e., the idea of bringing a pre-trained model (or a piece of it) to be part of another model. In the case of Mari the larger model is a computer vision model, e.g., ResNet, which is part of a variational quantum circuit that performs classification.
The work we present here follows a similar idea, but we focus in the autoencoder architecture, rather than a classification model, and we focus on learning representations in comparison between a classic and a variational quantum fine-tuned model.

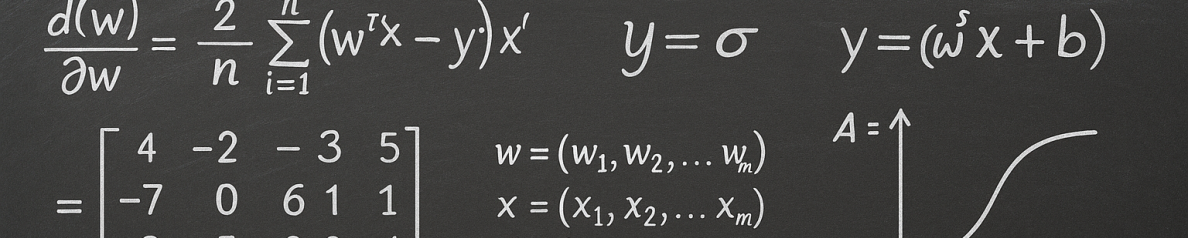

![\[\text{PSNR}=10\log_{10}\frac{\text{MAX}^2}{\text{MSE}}\]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-7898c1c1f5e8c4a261b8785f6d547dab_l3.png "Rendered by QuickLaTeX.com")




![\[ L = -\sum_{i=1}^{N}\frac{1}{|P(i)|}\sum_{p\in P(i)}\log\frac{\exp(\mathbf{z}_i\cdot\mathbf{z}_p/\tau)}{\sum_{a\in A(i)}\exp(\mathbf{z}_i\cdot\mathbf{z}_a/\tau)} \]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-05cc21b1de9e0f16c724022639be55b5_l3.png "Rendered by QuickLaTeX.com")
 is the embedding of the i‑th board state,
is the embedding of the i‑th board state,  denotes the set of positives (positions whose Stockfish evaluations differ by less than the margin = 0.05),
denotes the set of positives (positions whose Stockfish evaluations differ by less than the margin = 0.05),  is the full batch, and
is the full batch, and  is the temperature parameter. This supervised contrastive loss pulls together positions with similar evaluations and pushes apart those with dissimilar evaluations, shaping the latent space for geometric planning.
is the temperature parameter. This supervised contrastive loss pulls together positions with similar evaluations and pushes apart those with dissimilar evaluations, shaping the latent space for geometric planning.

 where each head is computed as:
where each head is computed as: 

 where
where  is the set of masked positions.
is the set of masked positions. given previous tokens
given previous tokens  . Objective Function:
. Objective Function: 
 .
. , modeling
, modeling  .
.![\mathcal{L}(\theta, \phi; x) = -\text{KL}(q_{\phi}(z|x) \| p_{\theta}(z)) + \mathbb{E}_{q_{\phi}(z|x)}[\log p_{\theta}(x|z)]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-92d0f4d5005687fea92672cd46704072_l3.png "Rendered by QuickLaTeX.com") where
where  is typically a standard normal prior
is typically a standard normal prior  .
. and a critic
and a critic  —competing in a minimax game.
—competing in a minimax game.![\min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{data}}}[\log D(x)] + \mathbb{E}_{z \sim p_z}[\log(1 - D(G(z)))]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-f4c6097b521f4afe7b8923e542639fb8_l3.png "Rendered by QuickLaTeX.com") where
where  is the data distribution and
is the data distribution and  is the prior over the latent space.
is the prior over the latent space. using neural networks. Bellman Equation:
using neural networks. Bellman Equation:  where
where  are the parameters of a target network.
are the parameters of a target network. directly. REINFORCE Algorithm Objective:
directly. REINFORCE Algorithm Objective: ![\nabla_{\theta} J(\theta) = \mathbb{E}_{\pi_{\theta}} \left[ \nabla_{\theta} \log \pi_{\theta}(a|s) R \right]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-e53cb7a1cae29f8595a1b83926e92a7f_l3.png "Rendered by QuickLaTeX.com") where
where  is the cumulative reward.
is the cumulative reward. where
where  and
and  are the batch mean and variance.
are the batch mean and variance. where
where  and
and  are computed over the features of a single sample.
are computed over the features of a single sample. and decoder state
and decoder state  . Common Score Functions:
. Common Score Functions:

![\text{score}(h, s) = v_a^\top \tanh(W_a [h; s])](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-c1390492617640d0676cb7559ef2b7e6_l3.png "Rendered by QuickLaTeX.com")
 where the attention weights
where the attention weights  are computed as:
are computed as: 
 where:
where:
 is the representation of node
is the representation of node  at layer
at layer  .
. is the set of neighbors of node
is the set of neighbors of node  and
and  are learnable weight matrices.
are learnable weight matrices. is a nonlinear activation function.
is a nonlinear activation function. where:
where:
 is the adjacency matrix with added self-loops.
is the adjacency matrix with added self-loops. is the degree matrix of
is the degree matrix of  .
.![\mathcal{L}_{i,j} = -\log \frac{\exp(\text{sim}(z_i, z_j)/\tau)}{\sum_{k=1}^{2N} \textbf{1}_{[k \neq i]} \exp(\text{sim}(z_i, z_k)/\tau)}](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-6a9932a8dfe6978287a7781d76d979c1_l3.png "Rendered by QuickLaTeX.com") where:
where:
 and
and  are representations of two augmented views of the same sample.
are representations of two augmented views of the same sample. is the cosine similarity.
is the cosine similarity.![\textbf{1}_{[k \neq i]}](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-bf75515a28c2f067b99872a895694ed8_l3.png "Rendered by QuickLaTeX.com") is an indicator function equal to 1 when
is an indicator function equal to 1 when  .
. provides
provides  -differential privacy if for all datasets
-differential privacy if for all datasets  differing on one element, and all measurable subsets
differing on one element, and all measurable subsets  :
: ![P[\mathcal{A}(D) \in S] \leq e^\epsilon P[\mathcal{A}(D') \in S] + \delta](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-fc3bfc99a2d0988d512d785abdbbe75c_l3.png "Rendered by QuickLaTeX.com")
 using local data
using local data  :
: 
 where:
where:
 is the number of samples at client
is the number of samples at client  is the total number of samples across all clients.
is the total number of samples across all clients. where
where  is obtained by:
is obtained by: 
 ,
,  ,
,  ,
,  ,
, 
 is the gradient at time step
is the gradient at time step  .
. and
and  are hyperparameters controlling the exponential decay rates.
are hyperparameters controlling the exponential decay rates. is the learning rate.
is the learning rate. is a small constant to prevent division by zero.
is a small constant to prevent division by zero. timesteps.
timesteps. 
 back to
back to  .
. ![\mathcal{L}_{\text{simple}} = \mathbb{E}_{t, x_0, \epsilon} \left[ \| \epsilon - \epsilon_\theta(x_t, t) \|^2 \right]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-ef4693d6547fa2ffa2c1970ed721c48e_l3.png "Rendered by QuickLaTeX.com") where:
where:
 is the model’s prediction of the noise at timestep
is the model’s prediction of the noise at timestep 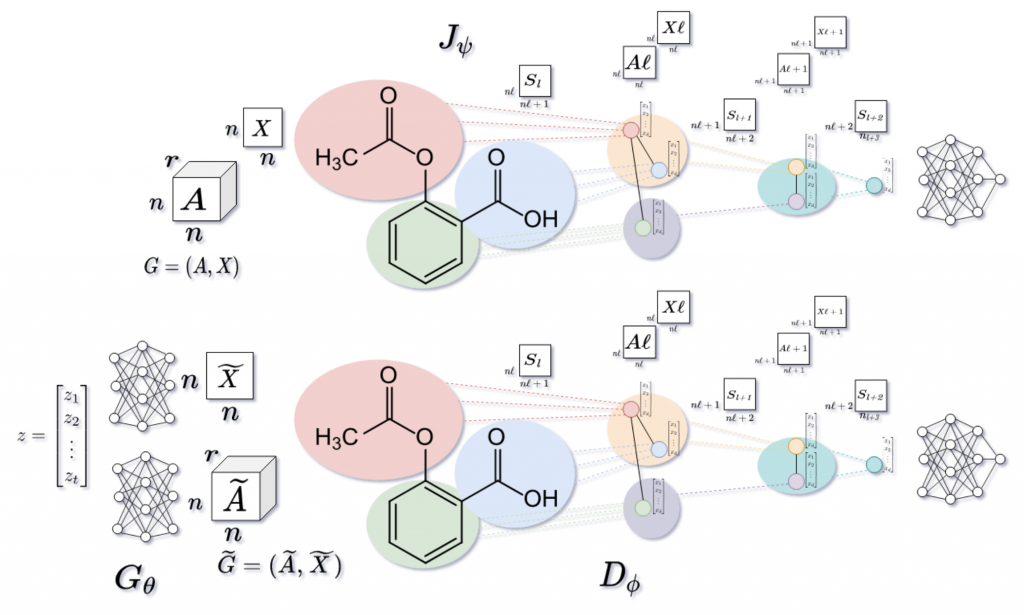



 produces a easible linear mapping to the desired target
produces a easible linear mapping to the desired target  as follows:
as follows:

 that need to be provided or learned. This enables the creation of some types of support vector machines whose kernels are calculated such that the data
that need to be provided or learned. This enables the creation of some types of support vector machines whose kernels are calculated such that the data  . The work of Schuld et al., expands the theory behind this idea an show that all kernel methods can be quantum machine learning methods.
Recently, in 2020, Mari et al., worked on variational models that are hybrid in format. Particularly, the authors focused on transfer learning, i.e., the idea of bringing a pre-trained model (or a piece of it) to be part of another model. In the case of Mari the larger model is a computer vision model, e.g., ResNet, which is part of a variational quantum circuit that performs classification.
The work we present here follows a similar idea, but we focus in the autoencoder architecture, rather than a classification model, and we focus on learning representations in comparison between a classic and a variational quantum fine-tuned model.
. The work of Schuld et al., expands the theory behind this idea an show that all kernel methods can be quantum machine learning methods.
Recently, in 2020, Mari et al., worked on variational models that are hybrid in format. Particularly, the authors focused on transfer learning, i.e., the idea of bringing a pre-trained model (or a piece of it) to be part of another model. In the case of Mari the larger model is a computer vision model, e.g., ResNet, which is part of a variational quantum circuit that performs classification.
The work we present here follows a similar idea, but we focus in the autoencoder architecture, rather than a classification model, and we focus on learning representations in comparison between a classic and a variational quantum fine-tuned model.