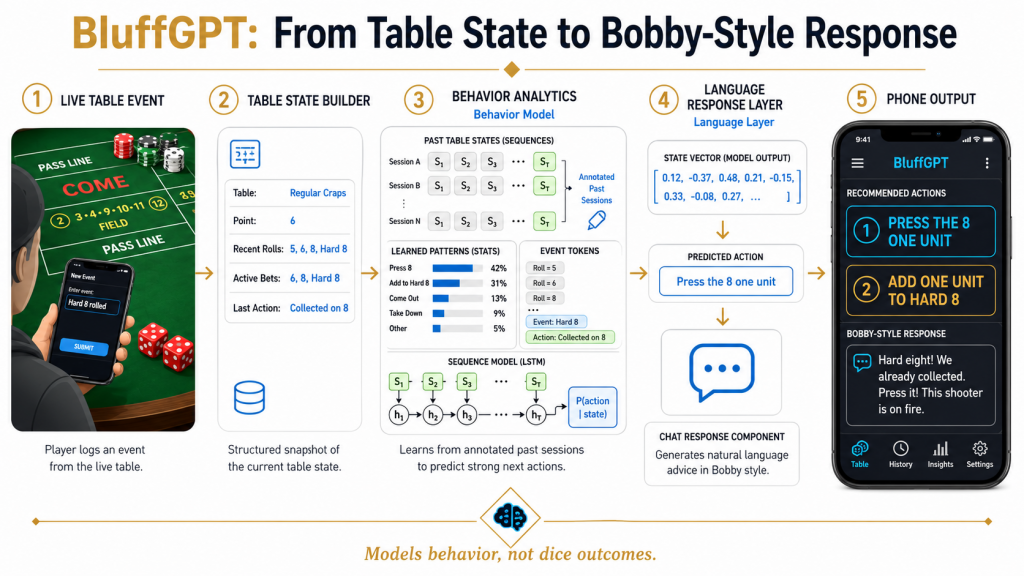
TL;DR: BluffGPT is a research concept for modeling how Bobby Rivas makes decisions at a craps table. Bobby or his staff enter each roll or table event into a phone. The system keeps track of the point, table type, recent rolls, active bets, and Bobby’s last action. It then predicts what Bobby would probably do next and generates a brief, high-energy response.
BluffGPT predicts Bobby’s likely behavior. It does not predict dice, promise better odds, or claim to beat the casino.
The Idea
Most chatbots answer questions. BluffGPT would do something different: it would track a changing game state and estimate what one specific player, Bobby, would probably do next.
The research question is simple:
Can an AI system learn Bobby’s betting patterns well enough to predict his next decision during a live craps session?
The system would study selected public craps sessions and their transcripts. The rolls, bets, and decisions shown in those sessions would be converted into structured events. These examples would help the model learn patterns such as when Bobby presses a number, collects a win, turns bets off, adds a hardway, or changes his action after a table event.
What the Phone Would Show
The phone interface would have two main sections.
The top section would summarize the current table state:
- Regular craps or crapless craps
- Current point
- Recent roll history
- Active bets
- Last betting action
- Current session state
The bottom section would work like a chat interface. A person could enter a short update such as:
Hard 8 rolled
BluffGPT would update the table state, predict Bobby’s next likely action, and return two parts:
- The suggested Bobby-style move
- A short response for the camera
The interface could also display a behavior-match score. This score would mean that the action is consistent with Bobby’s past behavior. It would not represent the probability that the bet will win.
How It Would Work
- Create structured examples. Selected public sessions would be reviewed and marked with the table type, point, dice result, active bets, prior action, and Bobby’s next decision.
- Maintain the live table state. Each new roll or event would update a compact state record containing the information needed by the model.
- Predict the next action. A behavior model would compare the current sequence with patterns found in prior sessions and select the most likely Bobby-style move.
- Check the game rules. A rules layer would make sure that the proposed action is valid for the table type, active bets, and stated limits.
- Generate the response. A language model would convert the selected action into a brief, energetic line suitable for a recorded episode.
The betting decision and the language response would therefore come from separate parts of the system. The behavior model would select the move. The language model would explain it.
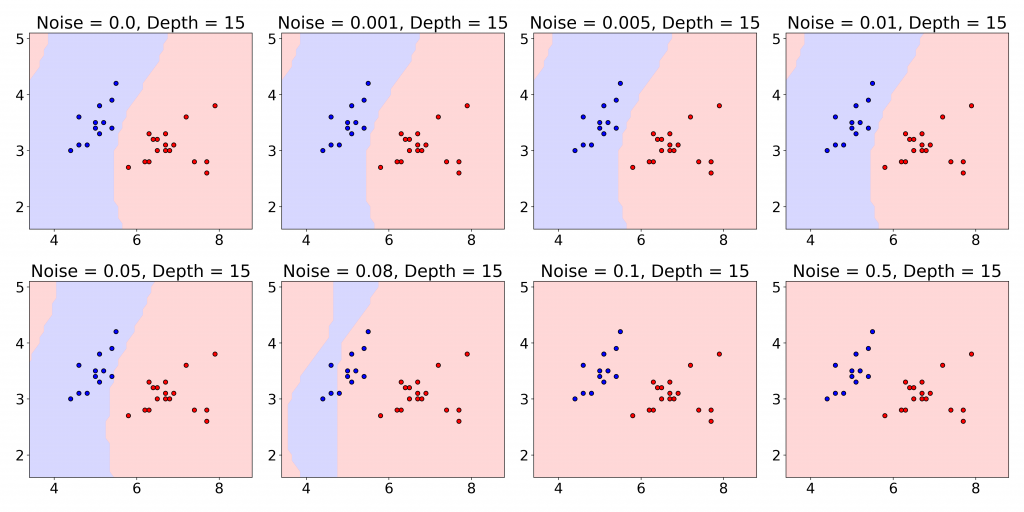
Example 1: A Hard Eight Rolls

Entered event:
Hard 8 rolled
Example table state:
- Table: Regular craps
- Point: 6
- Recent rolls: 5, 6, 8, hard 8
- Active bets: 6, 8, and hard 8
- Last action: Collected on the 8
Predicted move:
Press the 8 by one unit and add one unit to the hard 8.
Sample generated response:
“Hard eight! We already collected. Press it and let it run. This shooter is on fire.”
Example 2: Someone Buys In Mid-Roll

Not every decision is caused by the dice. The system could also track events involving other players or the flow of the table.
Entered event:
Someone is buying in mid-roll
Predicted move:
Turn all active bets off until the next clean roll.
Sample generated response:
“Oh my God. Someone is buying in mid-roll. I’m off. I’m off. Everything is off!”
This example shows why recent history and short-term memory matter. The model is responding to a table event and Bobby’s past reaction patterns, not only to a number on the dice.
Example 3: Aces Hit

Entered event:
Aces rolled
Example table state:
- Table: Crapless craps
- Point: 5
- Active aces bet: $500
- Last action: Maintained the aces bet
Predicted move:
Increase the aces bet to $1,000, if permitted by the table limits.
Sample generated response:
“Aces! We had five hundred on it! We’re rich baby! Take it to a thousand—one more time!”
The amounts shown in this example are sample interface values. They are not recommendations.
How the Model Would Be Tested
The model would be evaluated using sessions it did not see during development. At each betting decision, the system would receive the table state and recent history without seeing Bobby’s actual next move.
Its prediction would then be compared with what Bobby did in the video. The main result would be a behavioral match rate: how often the model selected the same type of action as Bobby.
Casino winnings would not be used as proof that the model is correct. A single session can produce very different financial results even when the same decisions are made.
Why This Is an AI Research Problem
This concept combines several AI tasks:
- Extracting structured events from video and transcripts
- Tracking a changing table state
- Modeling a person’s decisions across a sequence of events
- Estimating uncertainty in the predicted action
- Generating a brief response that matches an approved tone
- Checking that every proposed action follows the table rules
In machine learning terms, the system would be learning a behavioral policy from past examples. The goal is not to identify the best craps strategy. The goal is to estimate what Bobby would probably do.
Limits and Next Steps
Public videos may be edited, and the full table state may not always be visible. Two similar situations may also lead to different decisions. The model would therefore need to display uncertainty rather than claim that every prediction is certain.
The first version would use text input so that each roll and event can be entered clearly. A later version could add voice input or semi-automatic event detection.
A full production version would only be developed with Bobby’s approval, an agreed set of source material, an approved language guide, and clear rules for how the system may be used on camera.
FAQ
Can BluffGPT predict the next dice roll?
No. It predicts a person’s likely response to the current table state.
Does the language model select the bet?
No. A structured behavior model selects the action. The language model turns that action into a brief response.
Could it support both regular and crapless craps?
Yes. The table type would be part of the state, and a rules layer would restrict the model to actions that are valid for that table.
Is this gambling advice?
No. This is a research and entertainment concept for studying behavioral prediction.
Concept and initial prototype by Dr. Pablo Rivas, Rivas AI Lab. This independent concept has not been approved by or developed in partnership with Bobby Rivas, Bluff, Got Bluff, any casino, or any gaming operator. Sample statements and betting amounts are fictional interface examples.






 where each head is computed as:
where each head is computed as: 

 where
where  is the set of masked positions.
is the set of masked positions. given previous tokens
given previous tokens  . Objective Function:
. Objective Function: 
 .
. , modeling
, modeling  .
.![\mathcal{L}(\theta, \phi; x) = -\text{KL}(q_{\phi}(z|x) \| p_{\theta}(z)) + \mathbb{E}_{q_{\phi}(z|x)}[\log p_{\theta}(x|z)]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-92d0f4d5005687fea92672cd46704072_l3.png "Rendered by QuickLaTeX.com") where
where  is typically a standard normal prior
is typically a standard normal prior  .
. and a critic
and a critic  —competing in a minimax game.
—competing in a minimax game.![\min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{data}}}[\log D(x)] + \mathbb{E}_{z \sim p_z}[\log(1 - D(G(z)))]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-f4c6097b521f4afe7b8923e542639fb8_l3.png "Rendered by QuickLaTeX.com") where
where  is the data distribution and
is the data distribution and  is the prior over the latent space.
is the prior over the latent space. using neural networks. Bellman Equation:
using neural networks. Bellman Equation:  where
where  are the parameters of a target network.
are the parameters of a target network. directly. REINFORCE Algorithm Objective:
directly. REINFORCE Algorithm Objective: ![\nabla_{\theta} J(\theta) = \mathbb{E}_{\pi_{\theta}} \left[ \nabla_{\theta} \log \pi_{\theta}(a|s) R \right]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-e53cb7a1cae29f8595a1b83926e92a7f_l3.png "Rendered by QuickLaTeX.com") where
where  is the cumulative reward.
is the cumulative reward. where
where  and
and  are the batch mean and variance.
are the batch mean and variance. where
where  and
and  are computed over the features of a single sample.
are computed over the features of a single sample. and decoder state
and decoder state  . Common Score Functions:
. Common Score Functions:

![\text{score}(h, s) = v_a^\top \tanh(W_a [h; s])](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-c1390492617640d0676cb7559ef2b7e6_l3.png "Rendered by QuickLaTeX.com")
 where the attention weights
where the attention weights  are computed as:
are computed as: 
 where:
where:
 is the representation of node
is the representation of node  at layer
at layer  .
. is the set of neighbors of node
is the set of neighbors of node  and
and  are learnable weight matrices.
are learnable weight matrices. is a nonlinear activation function.
is a nonlinear activation function. where:
where:
 is the adjacency matrix with added self-loops.
is the adjacency matrix with added self-loops. is the degree matrix of
is the degree matrix of  .
.![\mathcal{L}_{i,j} = -\log \frac{\exp(\text{sim}(z_i, z_j)/\tau)}{\sum_{k=1}^{2N} \textbf{1}_{[k \neq i]} \exp(\text{sim}(z_i, z_k)/\tau)}](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-6a9932a8dfe6978287a7781d76d979c1_l3.png "Rendered by QuickLaTeX.com") where:
where:
 and
and  are representations of two augmented views of the same sample.
are representations of two augmented views of the same sample. is the cosine similarity.
is the cosine similarity. is a temperature parameter.
is a temperature parameter.![\textbf{1}_{[k \neq i]}](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-bf75515a28c2f067b99872a895694ed8_l3.png "Rendered by QuickLaTeX.com") is an indicator function equal to 1 when
is an indicator function equal to 1 when  .
. provides
provides  -differential privacy if for all datasets
-differential privacy if for all datasets  differing on one element, and all measurable subsets
differing on one element, and all measurable subsets  :
: ![P[\mathcal{A}(D) \in S] \leq e^\epsilon P[\mathcal{A}(D') \in S] + \delta](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-fc3bfc99a2d0988d512d785abdbbe75c_l3.png "Rendered by QuickLaTeX.com")
 using local data
using local data  :
: 
 where:
where:
 is the number of samples at client
is the number of samples at client  is the total number of samples across all clients.
is the total number of samples across all clients. where
where  is obtained by:
is obtained by: 
 ,
,  ,
,  ,
,  ,
, 
 is the gradient at time step
is the gradient at time step  .
. and
and  are hyperparameters controlling the exponential decay rates.
are hyperparameters controlling the exponential decay rates. is the learning rate.
is the learning rate. is a small constant to prevent division by zero.
is a small constant to prevent division by zero. timesteps.
timesteps. 
 back to
back to  .
. ![\mathcal{L}_{\text{simple}} = \mathbb{E}_{t, x_0, \epsilon} \left[ \| \epsilon - \epsilon_\theta(x_t, t) \|^2 \right]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-ef4693d6547fa2ffa2c1970ed721c48e_l3.png "Rendered by QuickLaTeX.com") where:
where:
 is the model’s prediction of the noise at timestep
is the model’s prediction of the noise at timestep 





![\[\min_{\mathcal{O}}\mathbb{E}[ \left | \langle{\psi}| \mathcal{O} |{\psi} \rangle - \langle{\psi} | \mathcal{O}_n |{\psi} \rangle ]\]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-3cfa5f0083acaa8744a5fc03feba12bf_l3.png "Rendered by QuickLaTeX.com")
 is a Pauli-Z observable, and
is a Pauli-Z observable, and  is an observable we are trying to learn. The expectation value is computed before and after noise is introduced. The goal is to find an observable that minimizes this difference, effectively learning a robust observable.
is an observable we are trying to learn. The expectation value is computed before and after noise is introduced. The goal is to find an observable that minimizes this difference, effectively learning a robust observable.
 . The expectation values of the observable
. The expectation values of the observable  on the depolarized Bell state as a function of the depolarization rate
on the depolarized Bell state as a function of the depolarization rate  are plotted in the following figure.
are plotted in the following figure.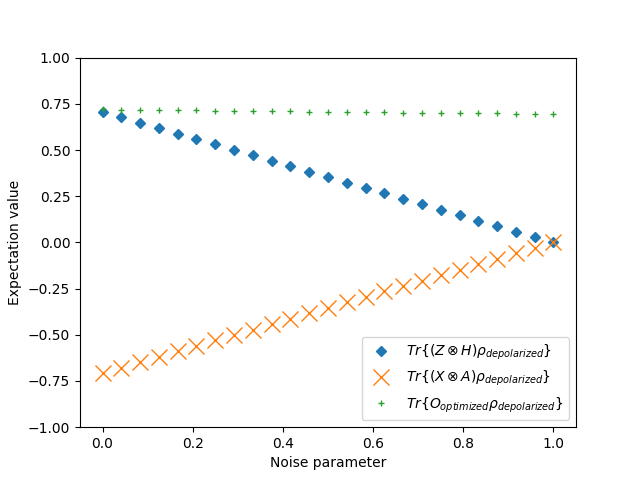
 is the Pauli-Z matrix,
is the Pauli-Z matrix,  is the Pauli-X matrix,
is the Pauli-X matrix,  is the Hadamard gate,
is the Hadamard gate,  is an arbitrary observable, and
is an arbitrary observable, and  . In the traditional depolarization model, noise can be introduced by applying the three Pauli matrices — X, Y, and Z to
. In the traditional depolarization model, noise can be introduced by applying the three Pauli matrices — X, Y, and Z to 

![\[\begin{array}{cc}K_0 = \sqrt{1 -\frac{2p}{3}} \mathbb{I}, &K_1 = i \sqrt{\frac{2p}{3}} ZX .\end{array}\]](https://lab.rivas.ai/wp-content/ql-cache/quicklatex.com-761f1150ca77b3315da52d621ec221e0_l3.png "Rendered by QuickLaTeX.com")